- L'agent ingénieur de classement (REA) by Meta effectue de manière autonome des étapes importantes dans tout le cycle de vie du machine learning (ML) pour les modèles de classement des annonces.
- Cet article couvre les capacités d'expérimentation ML de REA: génération autonome d'hypothèses, Démarrage d'emplois de formation, Erreurs de débogage et itération des résultats. Les prochains articles couvriront des fonctionnalités supplémentaires de REA.
- REA réduit le besoin d’intervention manuelle. Il gère les flux de travail asynchrones, qui s'étend sur des jours, voire des semaines, via un mécanisme de veille et de veille, assurer une surveillance humaine aux points de décision stratégiques clés.
- REA a livré le premier lancement de production:
- 2x précision du modèle: Les itérations basées sur REA ont doublé la précision moyenne du modèle par rapport à la référence sur six modèles.
- 5x production technique: Avec l'itération pilotée par REA, trois ingénieurs ont fourni des suggestions pour introduire des améliorations à huit modèles - un travail, qui dans le passé nécessitait deux ingénieurs par modèle.
Le goulot d'étranglement dans l'expérience ML traditionnelle
Le système publicitaire de Meta s'adresse à des milliards de personnes sur Facebook, Instagram, Expériences personnalisées Messenger et WhatsApp. Ces interactions s'effectuent à travers des, modèles d'apprentissage automatique complexes et massivement distribués (ML) prend en charge, qui évoluent continuellement, pour servir à la fois les annonceurs et les utilisateurs des plateformes.
L'optimisation de ces modèles ML prend traditionnellement beaucoup de temps. Les ingénieurs font des hypothèses, expériences de conception, commencer les courses d'entraînement, erreurs de débogage dans des bases de code complexes, analyser les résultats et itérer. Chaque cycle complet peut durer des jours ou des semaines. Les modèles Meta étant devenus plus sophistiqués au fil des années, c'est devenu de plus en plus difficile, pour trouver des améliorations significatives. Celui manuel, La nature séquentielle des expériences de ML traditionnelles est devenue un goulot d'étranglement pour l'innovation.
Pour résoudre ce problème, Meta a développé l'agent d'ingénierie de classement, un agent IA autonome, conçu pour piloter le cycle de vie du ML de bout en bout et faire évoluer de manière itérative les modèles de classement des annonces de Meta à grande échelle.
Présentation de REA: Un nouveau type d'agent autonome
De nombreux outils d'IA, qui sont utilisés aujourd'hui dans les workflows ML, agir en tant qu'assistants: Ils sont réactifs, liés à la tâche et à la session. Ils peuvent vous aider avec des étapes individuelles (z. B. lors de la conception d'une hypothèse, lors de l'écriture des fichiers de configuration, lors de l'interprétation des protocoles), mais ils ne peuvent généralement pas mener une expérience de manière cohérente. Un ingénieur doit encore décider, que faire ensuite, restaurez le contexte et stimulez la progression des tâches de longue durée - et corrigez les erreurs inévitables.
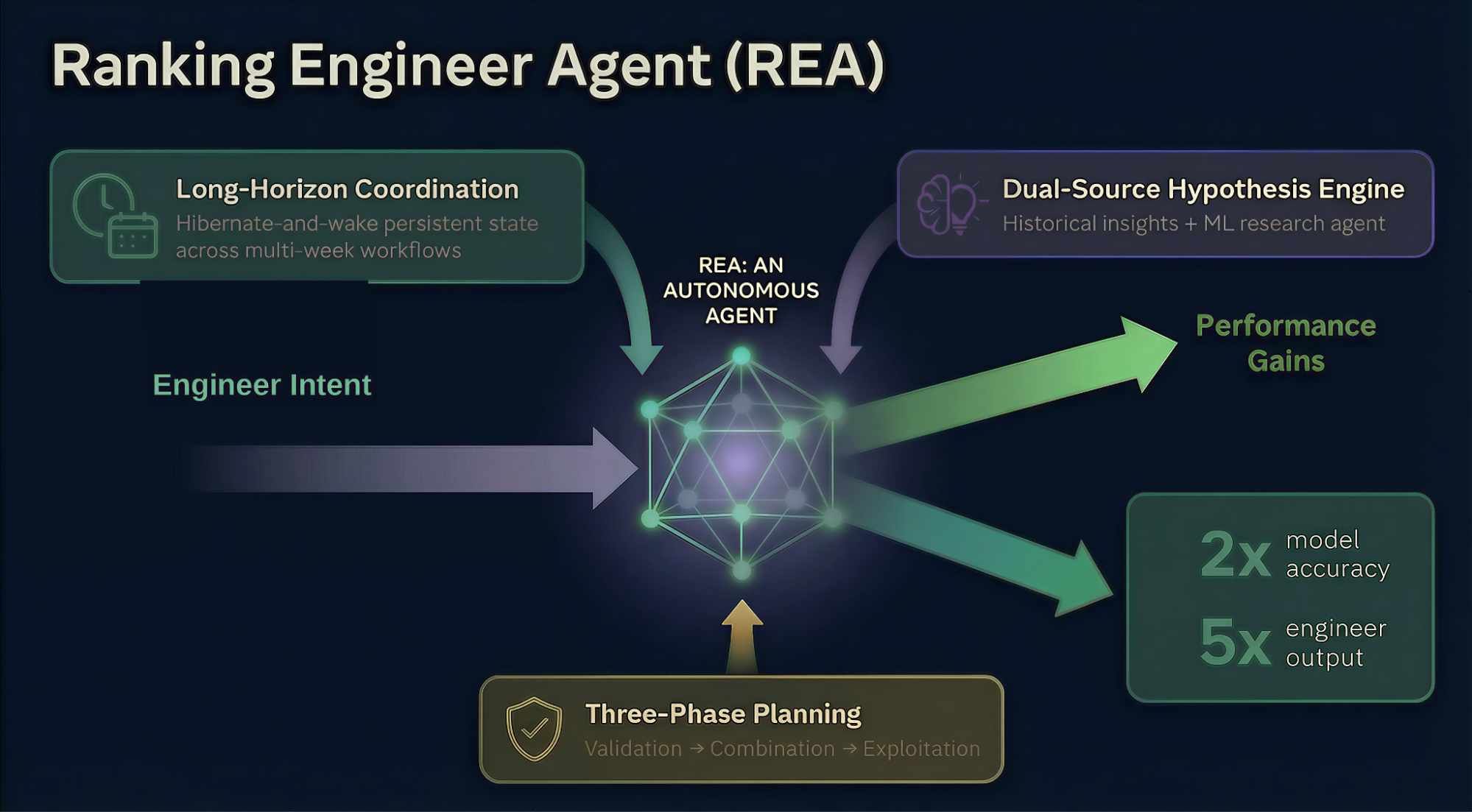
REA est différent: un agent autonome, qui dirige le cycle de vie du ML de bout en bout, en coordonnant et en pilotant des expériences de ML sur des flux de travail de plusieurs jours avec une intervention humaine minimale.
REA relève trois défis clés dans les expériences de ML autonomes:
- Long terme, Workflow-Autonomie asynchrone: Les tâches de formation ML durent quelques heures ou jours, bien au-delà de ça, ce qu'un assistant de session peut gérer. REA conserve l'état et la mémoire sur plusieurs flux de travail pendant des jours ou des semaines et reste coordonné sans surveillance humaine continue..
- Haute qualité, génération d'hypothèses diverses: La qualité d'une expérience est aussi bonne que l'hypothèse, qui le sous-tend. REA synthétise les résultats d'expériences historiques et de recherches révolutionnaires en ML sur les configurations de surface, qui ne découlent pas d’une approche unique, et s'améliore à chaque itération.
- Fonctionnement robuste dans les contraintes du monde réel: Pannes d'infrastructure, les erreurs inattendues et les budgets de calcul ne peuvent pas arrêter un agent autonome. REA s’adapte et assure dans le cadre de lignes directrices prédéfinies, que les processus de travail restent opérationnels, sans que les erreurs de routine soient répercutées sur les gens.
REA relève ces défis à travers un Mécanisme d'hibernation et de réveil pour un fonctionnement continu pendant plusieurs semaines, un Moteur d'hypothèse à double source qui combine une base de données d'informations historiques avec un agent de recherche approfondi en ML, et un Cadre de planification en trois phases (Validation → Combinaison → Exploitation), qui fonctionne dans les limites des budgets de calcul approuvés par l'ingénieur.
Comment REA gère de manière autonome les flux de travail ML sur plusieurs jours
REA est basé sur une vision centrale: L'optimisation complexe du ML n'est pas une tâche unique. C'est un processus en plusieurs étapes, qui s'étend sur des jours ou des semaines. L'agent doit penser à tout l'horizon, le plan, s'adapter et persévérer.
Autonomie du flux de travail à long terme
Les assistants IA traditionnels fonctionnent par courtes rafales, répondre aux invites, puis attendre la prochaine demande. Les expériences ML ne fonctionnent pas comme ça. Les missions de formation durent des heures ou des jours, et l'agent doit rester coordonné sur ces longues périodes de temps.
REA utilise un mécanisme de mise en veille prolongée et de réveil. Lorsque l'agent commence une tâche de formation, il délègue le temps d'attente à un système d'arrière-plan, s'arrête, pour économiser des ressources, et continue automatiquement là-bas une fois le travail terminé, où il s'est arrêté. Cela permet d'être efficace, fonctionnement continu sur de longues périodes, sans avoir besoin d'une surveillance humaine constante.
Pour soutenir cela, construit Meta REA sur un cadre d'agent IA interne. Confuciusconçu pour les complexes, tâches de réflexion à plusieurs niveaux. Il offre de puissantes capacités de génération de code et un SDK flexible pour l'intégration dans les systèmes d'outils internes de Meta., y compris les planificateurs d'emplois, Infrastructure de suivi des expériences et outils de navigation dans la base de code.
Haute qualité, génération d'hypothèses diverses
La qualité de l'hypothèse détermine directement la qualité d'une expérience ML. REA utilise deux systèmes spécialisés, générer des idées diverses et de qualité:
- Base de données de connaissances historiques: Un référentiel organisé d'expériences passées, qui permet un apprentissage contextuel et une reconnaissance de modèles à travers les succès et les échecs précédents.
- Agent de recherche ML: Un volet de recherche complet, qui examine les configurations fondamentales du modèle et propose de nouvelles stratégies d'optimisation en utilisant la méta-base de données d'informations historiques.
En synthétisant les informations des deux sources, les configurations REA deviennent visibles, qui sont peu susceptibles de découler d’une approche unique isolée. Les améliorations les plus marquantes de REA ont combiné des optimisations architecturales avec des techniques d'efficacité de la formation - résultat de cette méthodologie inter-systèmes..
Exécution résiliente dans le cadre des contraintes du monde réel
Les expériences du monde réel sont soumises à des limitations informatiques et à des erreurs inévitables. REA aborde à la fois la planification structurée et l’adaptation autonome.
Avant de mettre en œuvre un plan, REA propose une stratégie d'exploration détaillée, estime le coût total de calcul GPU et confirme la démarche avec un ingénieur. Un plan typique en plusieurs phases passe par trois phases:
- Validation: Des hypothèses individuelles provenant de différentes sources sont testées en parallèle, déterminer les bases de qualité.
- combinaison: Des hypothèses prometteuses se conjuguent, rechercher des améliorations synergiques.
- exploitation (optimisation intensive): Les candidats les plus prometteurs sont examinés de manière approfondie, maximiser les résultats dans le cadre du budget de calcul approuvé.
Lorsque REA rencontre des pannes – telles que des problèmes d’infrastructure, erreurs inattendues ou résultats sous-optimaux –, il adapte le plan selon des lignes directrices prédéfinies, au lieu d'attendre une intervention humaine. Il consulte un runbook avec des modèles d'erreur courants, prend des décisions de priorisation (z. B. exclusion des tâches comportant des erreurs évidentes en raison d'une mémoire insuffisante ou de signaux d'instabilité de formation tels que des explosions de pertes) et résout les pannes d'infrastructure provisoires dès le début. Cette résilience est cruciale pour maintenir l’autonomie lors de tâches de longue durée, où les ingénieurs assurent une supervision régulière plutôt qu’une surveillance continue.
REA travaille avec des précautions de sécurité strictes. Il fonctionne uniquement sur la base de code du modèle de classement des annonces de Meta.. Les ingénieurs fournissent des contrôles d'accès explicites grâce à des examens de listes de contrôle avant le vol, et REA confirme les budgets de calcul à l'avance et arrête ou met en pause les exécutions, lorsque les valeurs seuils sont atteintes.
L'architecture du système REA
![image[1]-Agent ingénieur de classement (REA): L'agent d'IA autonome accélère l'innovation de classement des annonces de Meta pour Windows 7,8,10,11-Winpcsoft.com](https://winpcsoft.com/wp-content/plugins/wp-fastest-cache-premium/pro/images/blank.gif)
Le Ranking Engineer Agent s’appuie sur deux composants interconnectés: Planificateur REA Et Exécuteur de la REAsoutenu par un commun capacité, connaissance- et système d'outils les fonctions ML, fournit des données d'expérience historiques et des intégrations avec l'infrastructure interne de Meta. Ensemble, ils activent directement les trois fonctions principales de l'agent.
Une autonomie à long terme est pris en charge par le flux d'exécution: Un ingénieur travaille avec le générateur d'hypothèses, pour créer un plan d'expérimentation détaillé à l'aide du REA Planner. Ce plan est exporté vers le REA Executor, qui gère l'exécution des travaux asynchrones via une boucle d'agent et un état d'attente, passe en état d'attente pendant les entraînements et continue avec les résultats une fois terminé, plutôt que d'exiger une supervision humaine continue sur des flux de travail de plusieurs semaines.
Haute qualité, génération d'hypothèses diverses est contrôlé par le flux de connaissances: Pendant que l'artiste réalise des expériences, un enregistreur d'expérience spécial enregistre les résultats, Indicateurs et configurations clés dans une base de données centrale d'informations sur les expériences d'hypothèses. Cette mémoire persistante collecte des connaissances sur l'ensemble de l'historique des opérations des agents.. Le générateur d'hypothèses utilise ces résultats, pour identifier des modèles, apprendre des succès et des échecs précédents et proposer des hypothèses de plus en plus sophistiquées pour chaque tour suivant, bouclant ainsi la boucle et améliorant l'intelligence du système au fil du temps.
Conception résiliente est maintenu dans les deux processus: Si l'exécuteur testamentaire rencontre des échecs, Défaillance des infrastructures, signaux concernant une mémoire insuffisante ou une instabilité de l'entraînement, il consulte un runbook avec des modèles d'erreur courants et applique une logique de priorisation, s’adapter de manière autonome selon des lignes directrices prédéfinies. Le planificateur continue ensuite avec des résultats exploitables, au lieu de signaler les interruptions de routine aux ingénieurs.
impact: Précision du modèle et productivité technique
Deux fois la précision du modèle par rapport aux approches de référence
Lors de la validation initiale de la production sur un ensemble de six modèles, les itérations basées sur REA ont doublé la précision moyenne du modèle par rapport aux approches de base.. Cela conduit directement à de meilleurs résultats pour les annonceurs et à de meilleures expériences sur les métaplateformes..
5-multiplication par deux de la productivité en ingénierie
REA augmente l'effet, en automatisant les mécanismes d'expérimentation du ML et en permettant aux ingénieurs, se concentrer sur la résolution créative de problèmes et la réflexion stratégique. Améliorations architecturales complexes, qui nécessitait auparavant plusieurs ingénieurs sur plusieurs semaines, peut désormais être réalisé par des équipes plus petites en quelques jours.
Utilisateurs précoces, utiliser le REA, ont augmenté leurs suggestions d'amélioration du modèle de une à cinq au cours de la même période. Pour le travail, qui nécessitait auparavant deux ingénieurs par modèle, trois ingénieurs sont désormais requis sur huit modèles.
L'avenir de la collaboration homme-IA dans l'ingénierie ML
REA représente un changement dans l'approche de Meta en matière d'ingénierie ML. En développant des agents, qui peut gérer de manière autonome l’ensemble du cycle de vie de l’expérimentation, L'équipe modifie la structure du développement du ML, faisant passer les ingénieurs de l'expérimentation pratique à la supervision stratégique., Orientation d’hypothèses et prise de décision architecturale.
Ce nouveau paradigme, où les agents gèrent des mécanismes itératifs, pendant que les gens prennent des décisions stratégiques et des approbations finales, ce n'est que le début. Protection des données, La sécurité et la gouvernance restent la priorité absolue de l'agent. Meta continue d'améliorer les capacités de REA, en affinant des modèles spécifiques pour la génération d'hypothèses, Outils d’analyse élargis et approche élargie à de nouveaux domaines.
Remerciements
Ashwin Kumar, Harpal Bassali, Shashank Ankit, Deepak Chandra, Chaorong Chen, Wenlin Chen, Victor Cid, Peter Chu, Xiaoyu Deng, Jingyi Guan, Junhua Gu, Liquan Huang, Jia Qinjin, Santanu Kolay, Jacob Moberg, Shweta Mémane, Jp dû, Sandeep Pandey, Vijay Pappu, Shyam Rajaram, Ben Schulte, Jags Somadder, Matt Steiner, Ritwik Tewari, Hangjun Xu, Zhaodong Wang, Fan Yang, Xin Zhao, Zoé Zu