- O agente engenheiro de classificação (REA) by Meta executa de forma autônoma etapas importantes em todo o ciclo de vida do aprendizado de máquina (AM) para modelos de classificação de anúncios.
- Esta postagem aborda os recursos de experimentação de ML da REA: geração autônoma de hipóteses, Iniciando trabalhos de treinamento, Depurando erros e iterando resultados. Postagens futuras cobrirão recursos adicionais do REA.
- REA reduz a necessidade de intervenção manual. Ele gerencia fluxos de trabalho assíncronos, que se estendem por dias a semanas, através de um mecanismo de dormir e acordar, garantindo a supervisão humana nos principais pontos de decisão estratégica.
- REA entregou o primeiro lançamento de produção:
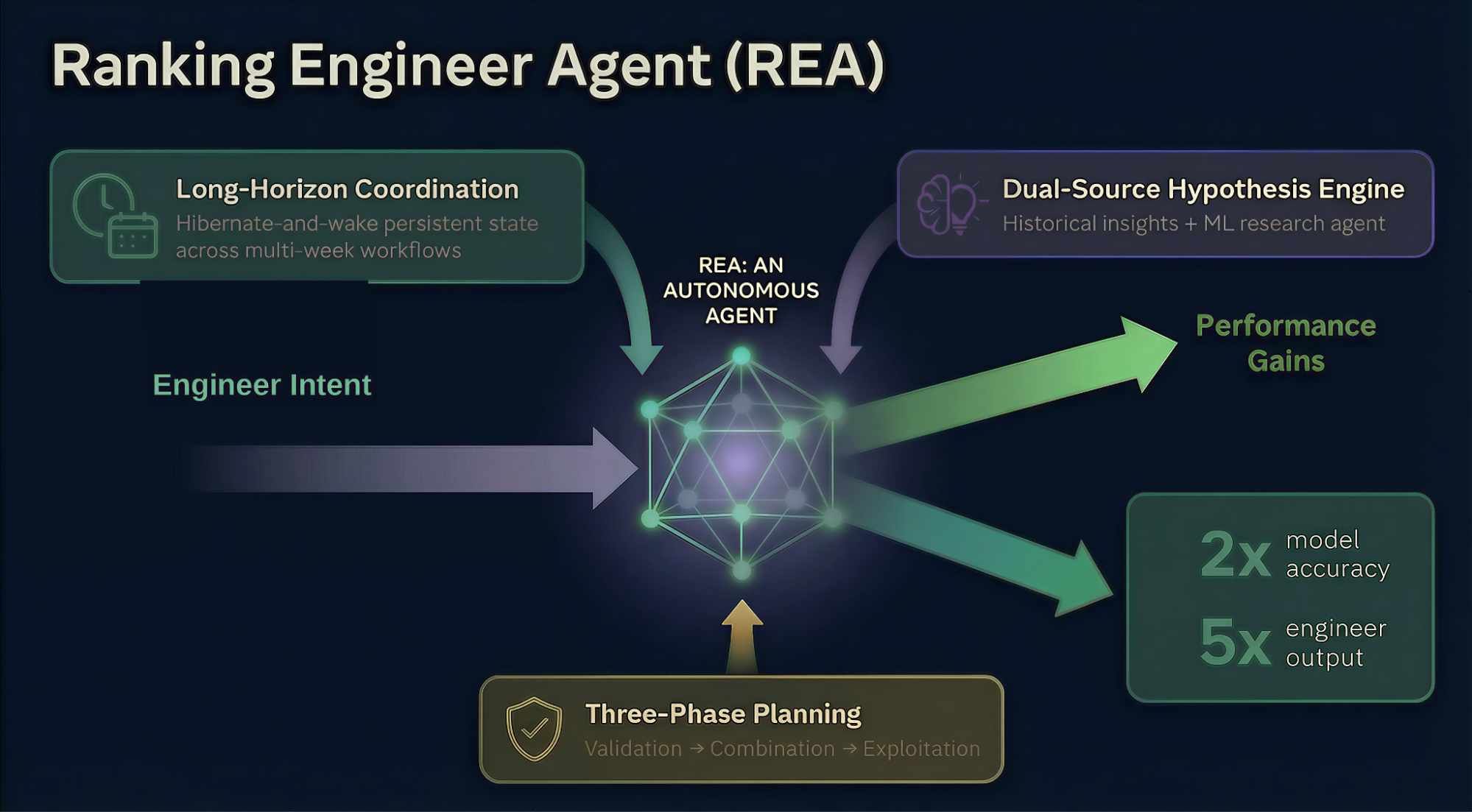
- 2x precisão do modelo: As iterações orientadas por REA dobraram a precisão média do modelo em relação à linha de base em seis modelos.
- 5x produção técnica: Com a iteração orientada pelo REA, três engenheiros forneceram sugestões para a introdução de melhorias em oito modelos - um trabalho, que no passado exigia dois engenheiros por modelo.
O gargalo no experimento tradicional de ML
O sistema de publicidade da Meta atende bilhões de pessoas no Facebook, Instagram, Experiências personalizadas no Messenger e WhatsApp. Essas interações são realizadas através de sistemas altamente sofisticados, modelos de aprendizado de máquina complexos e massivamente distribuídos (AM) suporta, que estão em constante evolução, para atender anunciantes e usuários das plataformas.
A otimização desses modelos de ML tem sido tradicionalmente demorada. Engenheiros fazem hipóteses, experimentos de design, começar corridas de treinamento, depurar erros em bases de código complexas, analisar resultados e iterar. Cada ciclo completo pode durar dias a semanas. À medida que os modelos da Meta se tornaram mais sofisticados ao longo dos anos, tornou-se cada vez mais difícil, para encontrar melhorias significativas. O manual, A natureza sequencial dos experimentos tradicionais de ML tornou-se um gargalo para a inovação.
Para resolver este problema, Meta desenvolveu o Agente Engenheiro de Classificação, um agente de IA autônomo, projetado para impulsionar o ciclo de vida de ML de ponta a ponta e evoluir iterativamente os modelos de classificação de anúncios da Meta em escala.
Apresentando REA: Um novo tipo de agente autônomo
Muitas ferramentas de IA, que são usados em fluxos de trabalho de ML hoje, atuar como assistentes: Eles são reativos, relacionado à tarefa e relacionado à sessão. Eles podem ajudar com etapas individuais (z. B. ao projetar uma hipótese, ao escrever arquivos de configuração, ao interpretar protocolos), mas geralmente eles não conseguem realizar um experimento de forma consistente. Um engenheiro ainda precisa decidir, o que fazer a seguir, restaure o contexto e impulsione o progresso em trabalhos de longa duração - e corrija erros inevitáveis.
REA é diferente: um agente autônomo, que conduz o ciclo de vida de ML de ponta a ponta, coordenando e conduzindo experimentos de ML em fluxos de trabalho de vários dias com intervenção humana mínima.
REA aborda três desafios principais em experimentos de ML autônomos:
- Longo prazo, Autonomia de fluxo de trabalho assíncrono: Os trabalhos de treinamento de ML duram horas ou dias, muito além disso, o que um assistente de sessão pode lidar. O REA persiste no estado e na memória em vários fluxos de trabalho durante dias ou semanas e permanece coordenado sem supervisão humana contínua.
- Alta qualidade, geração de hipóteses diversas: A qualidade de um experimento é tão boa quanto a hipótese, que lhe está subjacente. REA sintetiza resultados de experimentos históricos e pesquisas inovadoras de ML sobre configurações de superfície, que não surgem de uma abordagem única, e melhora a cada iteração.
- Operação robusta dentro das restrições do mundo real: Falhas de infraestrutura, erros inesperados e orçamentos computacionais não podem impedir um agente autônomo. REA se adapta e garante dentro de diretrizes predefinidas, que os processos de trabalho permaneçam em execução, sem que erros rotineiros sejam repassados às pessoas.
A REA aborda estes desafios através de uma Mecanismo de hibernação e ativação para operação contínua com duração de várias semanas, um Motor de hipótese de fonte dupla que combina um banco de dados de insights históricos com um profundo agente de pesquisa de ML, e um Estrutura de planejamento trifásico (Validação → Combinação → Exploração), que opera dentro dos orçamentos computacionais aprovados pelo engenheiro.
Como a REA gerencia de forma autônoma fluxos de trabalho de ML de vários dias
REA é baseado em uma visão central: A otimização complexa de ML não é uma tarefa única. É um processo de várias etapas, que se estende por dias ou semanas. O agente tem que pensar em todo o horizonte, o plano, adaptar e perseverar.
Autonomia de fluxo de trabalho a longo prazo
Assistentes de IA tradicionais trabalham em períodos curtos, responda às solicitações e aguarde a próxima solicitação. Experimentos de ML não funcionam assim. As tarefas de treinamento duram horas ou dias, e o agente deve permanecer coordenado durante esses longos períodos de tempo.
REA usa um mecanismo de hibernação e ativação. Quando o agente inicia um trabalho de treinamento, delega o tempo de espera a um sistema em segundo plano, desliga, para economizar recursos, e continua automaticamente lá depois que o trabalho for concluído, onde ele parou. Isto permite eficiência, operação contínua por longos períodos de tempo, sem a necessidade de supervisão humana constante.
Para apoiar isso, construiu o Meta REA em uma estrutura interna de agente de IA. Confúcioprojetado para complexos, tarefas de pensamento multinível. Oferece recursos poderosos de geração de código e um SDK flexível para integração aos sistemas de ferramentas internos da Meta, einschließlich Jobplanern, Infraestrutura de rastreamento de experimentos e ferramentas de navegação de base de código.
Alta qualidade, geração de hipóteses diversas
A qualidade da hipótese determina diretamente a qualidade de um experimento de ML. REA usa dois sistemas especializados, para gerar ideias diversas e de alta qualidade:
- Banco de dados de conhecimento histórico: Um repositório com curadoria de experimentos anteriores, que permite a aprendizagem contextual e o reconhecimento de padrões em sucessos e fracassos anteriores.
- Agente de pesquisa de ML: Um componente de pesquisa abrangente, que examina configurações fundamentais do modelo e propõe novas estratégias de otimização usando o meta-banco de dados de insights históricos.
Ao sintetizar insights de ambas as fontes, as configurações do REA tornam-se visíveis, que provavelmente não surgirão de uma abordagem única isoladamente. As melhorias mais impactantes do REA combinaram otimizações arquitetônicas com técnicas de eficiência de treinamento - resultado desta metodologia entre sistemas.
Execução resiliente dentro das restrições do mundo real
Experimentos do mundo real estão sujeitos a limitações computacionais e erros inevitáveis. A REA aborda tanto através de planeamento estruturado como de adaptação autónoma.
Antes de implementar um plano, a REA propõe uma estratégia de exploração detalhada, estima o custo total de computação da GPU e confirma a abordagem com um engenheiro. Um plano multifásico típico passa por três fases:
- Validação: Hipóteses individuais de diferentes fontes são testadas em paralelo, para determinar bases de qualidade.
- combinação: Hipóteses promissoras são combinadas, buscar melhorias sinérgicas.
- exploração (otimização intensiva): Os candidatos mais promissores são examinados intensivamente, maximizar resultados dentro do orçamento computacional aprovado.
Quando a REA encontra falhas – como problemas de infraestrutura, erros inesperados ou resultados abaixo do ideal –, adapta o plano dentro de diretrizes predefinidas, em vez de esperar pela intervenção humana. Consulta um runbook com padrões de erros comuns, toma decisões de priorização (z. B. excluindo trabalhos com erros claros devido a memória insuficiente ou sinais de instabilidade de treinamento, como explosões de perda) e resolve falhas provisórias de infraestrutura desde o início. Esta resiliência é crucial para manter a autonomia durante tarefas de longo prazo, onde os engenheiros fornecem supervisão regular em vez de monitoramento contínuo.
A REA trabalha com rigorosas precauções de segurança. Funciona exclusivamente na base de código do modelo de classificação de anúncios do Meta. Engenheiros fornecem controles de acesso explícitos por meio de revisões de listas de verificação pré-voo, e REA confirma os orçamentos computacionais antecipadamente e interrompe ou pausa as execuções, quando os valores limite são atingidos.
A arquitetura do sistema REA
![foto[1]-Agente Engenheiro de Classificação (REA): O agente autônomo de IA acelerando a inovação na classificação de anúncios da Meta para Windows 7,8,10,11-Winpcsoft.com](https://winpcsoft.com/wp-content/plugins/wp-fastest-cache-premium/pro/images/blank.gif)
O Ranking Engineer Agent é baseado em dois componentes interconectados: REA-Planer E Executor de REAapoiado por um comum habilidade, conhecimento- e sistema de ferramentas as funções de ML, fornece dados históricos de experimentos e integrações com a infraestrutura interna da Meta. Juntos, eles permitem diretamente as três funções principais do agente.
Autonomia num longo horizonte é suportado pelo fluxo de execução: Um engenheiro trabalha com o gerador de hipóteses, para criar um plano de experimento detalhado usando o REA Planner. Este plano é exportado para o REA Executor, que gerencia a execução assíncrona do trabalho por meio de um loop de agente e um estado de espera, muda para um estado de espera durante as execuções de treinamento e continua com os resultados após a conclusão, em vez de exigir supervisão humana contínua em fluxos de trabalho de várias semanas.
Alta qualidade, geração de hipóteses diversas é controlado pelo fluxo de conhecimento: Enquanto o artista completa experimentos, um registrador de experimentos especial registra os resultados, Principais métricas e configurações em um banco de dados central de insights de experimentos de hipóteses. Esta memória persistente coleta conhecimento sobre todo o histórico de operações do agente. O gerador de hipóteses usa essas descobertas, para identificar padrões, aprender com os sucessos e fracassos anteriores e propor hipóteses cada vez mais sofisticadas para cada rodada subsequente, fechando assim o ciclo e melhorando a inteligência do sistema ao longo do tempo.
Design resiliente é mantido em ambos os processos: Se o executor encontrar falhas, Falha de infraestrutura, sinais sobre memória insuficiente ou instabilidade de treinamento, ele consulta um runbook com padrões de erros comuns e aplica lógica de priorização, adaptar-se autonomamente dentro de diretrizes predefinidas. O planejador então continua com resultados acionáveis, em vez de apontar interrupções de rotina aos engenheiros.
impacto: Precisão do modelo e produtividade técnica
O dobro da precisão do modelo em comparação com abordagens de linha de base
Na validação inicial da produção em um conjunto de seis modelos, as iterações orientadas por REA duplicaram a precisão média do modelo em comparação com as abordagens de linha de base. Isso leva diretamente a melhores resultados para os anunciantes e melhores experiências em metaplataformas.
5-dobrar o aumento da produtividade na engenharia
REA aumenta o efeito, automatizando a mecânica da experimentação de ML e permitindo que os engenheiros, focar na resolução criativa de problemas e no pensamento estratégico. Komplexe Architekturverbesserungen, que anteriormente exigia vários engenheiros durante várias semanas, agora pode ser concluído por equipes menores em poucos dias.
Adeptos pioneiros, use o REA, aumentaram suas sugestões para melhoria do modelo de um para cinco no mesmo período. Para o trabalho, que anteriormente exigia dois engenheiros por modelo, agora são necessários três engenheiros em oito modelos.
O futuro da colaboração humano-IA na engenharia de ML
REA representa uma mudança na abordagem da Meta para engenharia de ML. Ao desenvolver agentes, que pode gerenciar de forma autônoma todo o ciclo de vida da experimentação, A equipe está mudando a estrutura de desenvolvimento de ML, transferindo os engenheiros da experimentação prática para a supervisão estratégica, Orientação de hipóteses e tomada de decisão arquitetônica.
Este novo paradigma, onde os agentes gerenciam mecanismos iterativos, à medida que as pessoas tomam decisões estratégicas e aprovações finais, é apenas o começo. Proteção de dados, Segurança e governança continuam sendo a principal prioridade do agente. Meta continua a melhorar as capacidades da REA, refinando modelos específicos para geração de hipóteses, As ferramentas de análise foram ampliadas e a abordagem expandida para novas áreas.
Agradecimentos
Ashwin Kumar, Harpal Bassali, Shashank Ankit, Deepak Chandra, Chaorong Chen, Wen Lin Chen, Vitor Cid, Pedro Chu, Xiao Yu Deng, Jingyi Guan, Junhua Gu, Liquan Huang, Qinjin Jia, Santanu Kolay, Jakob Moberg, Shweta Memane, Jp devido, Sandeep Pandey, Vijay Pappu, Shyam Rajaram, Ben Schulte, Jags Somadder, Matt Steiner, Ritwik Tewari, Hangjun Xu, Zhaodong Wang, Ventilador Yang, Xin Zhao, Zoe Zu