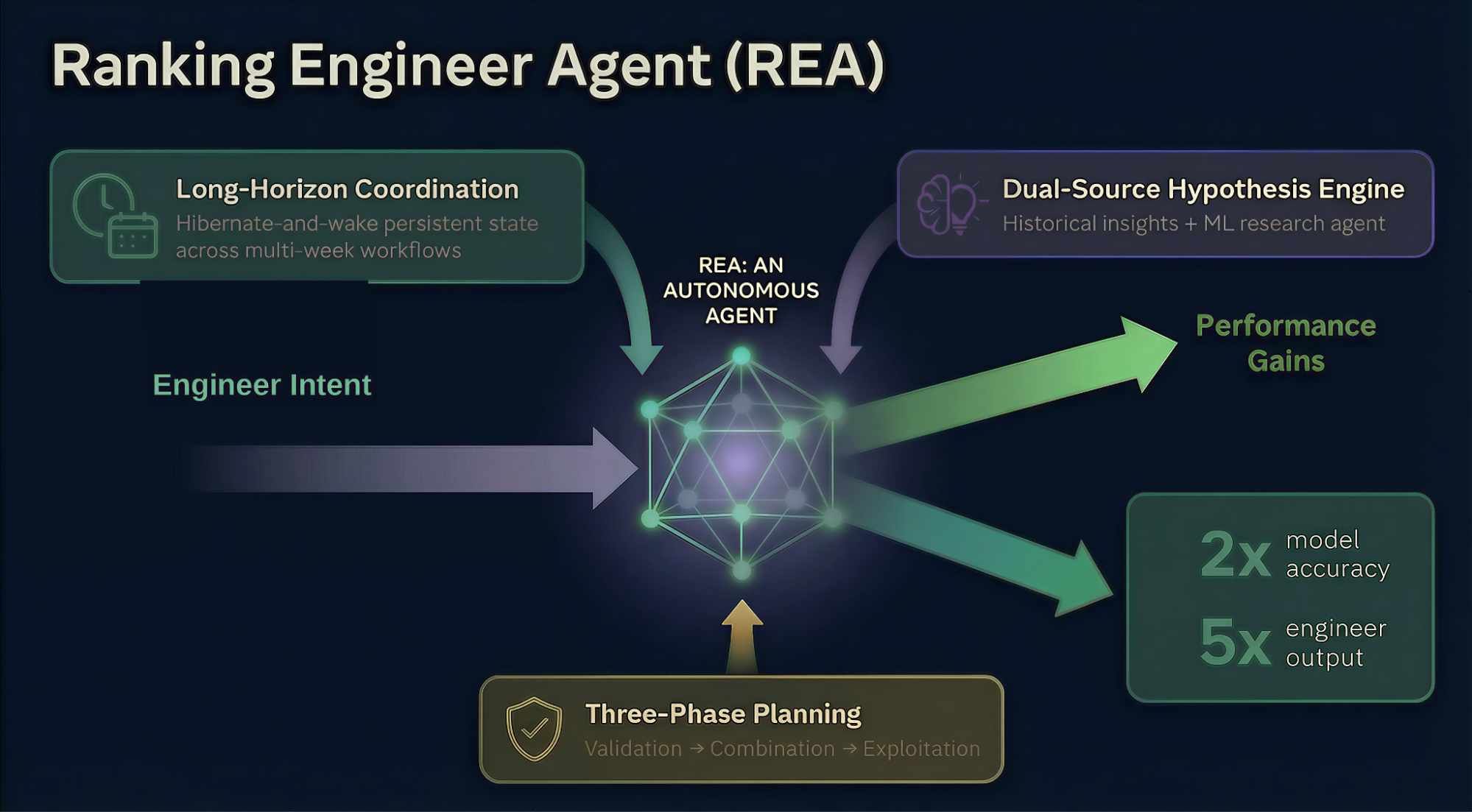
- Der Ranking Engineer Agent (REA) von Meta führt autonom wichtige Schritte im gesamten Lebenszyklus des maschinellen Lernens (ML) für Anzeigenranking-Modelle aus.
- Dieser Beitrag behandelt die ML-Experimentierfunktionen von REA: autonomes Generieren von Hypothesen, Starten von Trainingsjobs, Debuggen von Fehlern und Iterieren von Ergebnissen. Zukünftige Beiträge werden zusätzliche REA-Funktionen behandeln.
- REA reduziert die Notwendigkeit manueller Eingriffe. Es verwaltet asynchrone Arbeitsabläufe, die sich über Tage bis Wochen erstrecken, über einen Ruhezustand-und-Wach-Mechanismus, wobei an wichtigen strategischen Entscheidungspunkten die menschliche Aufsicht gewährleistet ist.
- Bei der ersten Produktionseinführung lieferte REA:
- 2x Modellgenauigkeit: REA-gesteuerte Iterationen verdoppelten die durchschnittliche Modellgenauigkeit gegenüber dem Ausgangswert bei sechs Modellen.
- 5x technischer Output: Mit der REA-gesteuerten Iteration lieferten drei Ingenieure Vorschläge zur Einführung von Verbesserungen für acht Modelle – eine Arbeit, für die in der Vergangenheit zwei Ingenieure pro Modell erforderlich waren.
Der Engpass im traditionellen ML-Experiment
Das Werbesystem von Meta bietet Milliarden von Menschen auf Facebook, Instagram, Messenger und WhatsApp personalisierte Erlebnisse. Diese Interaktionen werden durch hochentwickelte, komplexe und massiv verteilte Modelle des maschinellen Lernens (ML) unterstützt, die sich kontinuierlich weiterentwickeln, um sowohl Werbetreibenden als auch Nutzern der Plattformen zu dienen.
Die Optimierung dieser ML-Modelle war traditionell zeitaufwändig. Ingenieure stellen Hypothesen auf, entwerfen Experimente, starten Trainingsläufe, debuggen Fehler in komplexen Codebasen, analysieren Ergebnisse und iterieren. Jeder vollständige Zyklus kann Tage bis Wochen dauern. Da die Modelle von Meta im Laufe der Jahre ausgereifter wurden, ist es immer schwieriger geworden, sinnvolle Verbesserungen zu finden. Der manuelle, sequentielle Charakter traditioneller ML-Experimente ist zu einem Engpass für Innovationen geworden.
Um dieses Problem anzugehen, hat Meta den Ranking Engineer Agent entwickelt, einen autonomen KI-Agenten, der den End-to-End-ML-Lebenszyklus vorantreiben und Metas Anzeigenranking-Modelle iterativ in großem Maßstab weiterentwickeln soll.
Wir stellen REA vor: Eine neue Art von autonomem Agenten
Viele KI-Tools, die heute in ML-Workflows eingesetzt werden, fungieren als Assistenten: Sie sind reaktiv, aufgabenbezogen und sitzungsgebunden. Sie können bei einzelnen Schritten helfen (z. B. beim Entwerfen einer Hypothese, beim Schreiben von Konfigurationsdateien, beim Interpretieren von Protokollen), aber normalerweise können sie ein Experiment nicht durchgängig durchführen. Ein Ingenieur muss immer noch entscheiden, was als nächstes zu tun ist, den Kontext wiederherstellen und den Fortschritt bei lang laufenden Jobs vorantreiben – und unvermeidliche Fehler beheben.
REA ist anders: ein autonomer Agent, der den End-to-End-ML-Lebenszyklus vorantreibt und ML-Experimente über mehrtägige Arbeitsabläufe hinweg mit minimalem menschlichen Eingriff koordiniert und vorantreibt.
REA befasst sich mit drei zentralen Herausforderungen bei autonomen ML-Experimenten:
- Langfristige, asynchrone Workflow-Autonomie: ML-Trainingsjobs dauern Stunden oder Tage, weit über das, was ein sitzungsgebundener Assistent bewältigen kann. REA behält den Zustand und Speicher über mehrere Arbeitsabläufe hinweg über Tage oder Wochen hinweg dauerhaft bei und bleibt ohne kontinuierliche menschliche Aufsicht koordiniert.
- Hochwertige, vielfältige Hypothesengenerierung: Die Qualität eines Experiments ist nur so gut wie die Hypothese, die ihm zugrunde liegt. REA synthetisiert Ergebnisse historischer Experimente und bahnbrechender ML-Forschung zu Oberflächenkonfigurationen, die sich aus keinem einzelnen Ansatz ergeben, und verbessert sich mit jeder Iteration.
- Robuster Betrieb innerhalb realer Einschränkungen: Infrastrukturausfälle, unerwartete Fehler und Rechenbudgets können einen autonomen Agenten nicht aufhalten. REA passt sich innerhalb vordefinierter Leitplanken an und sorgt dafür, dass Arbeitsabläufe in Gang bleiben, ohne dass Routinefehler auf den Menschen übertragen werden.
REA begegnet diesen Herausforderungen durch a Hibernate-and-Wake-Mechanismus für einen mehrwöchigen Dauerbetrieb, a Dual-Source-Hypothese-Engine das eine Datenbank mit historischen Erkenntnissen mit einem tiefgreifenden ML-Forschungsagenten kombiniert, und a Drei-Phasen-Planungsrahmen (Validierung → Kombination → Ausnutzung), die innerhalb der vom Ingenieur genehmigten Rechenbudgets arbeitet.
Wie REA mehrtägige ML-Workflows autonom verwaltet
REA basiert auf einer zentralen Erkenntnis: Komplexe ML-Optimierung ist keine einzelne Aufgabe. Es handelt sich um einen mehrstufigen Prozess, der sich über Tage oder Wochen erstreckt. Der Agent muss über den gesamten Horizont nachdenken, planen, sich anpassen und durchhalten.
Langfristige Workflow-Autonomie
Herkömmliche KI-Assistenten arbeiten in kurzen Stößen, reagieren auf Eingabeaufforderungen und warten dann auf die nächste Anfrage. ML-Experimente funktionieren so nicht. Schulungsaufträge dauern Stunden oder Tage, und der Agent muss über diese langen Zeiträume hinweg koordiniert bleiben.
REA verwendet einen Hibernate-and-Wake-Mechanismus. Wenn der Agent einen Trainingsjob startet, delegiert er die Wartezeit an ein Hintergrundsystem, fährt herunter, um Ressourcen zu sparen, und setzt nach Abschluss des Jobs automatisch dort fort, wo er aufgehört hat. Dies ermöglicht einen effizienten, kontinuierlichen Betrieb über längere Zeiträume hinweg, ohne dass eine ständige menschliche Überwachung erforderlich ist.
Um dies zu unterstützen, baute Meta REA auf einem internen KI-Agenten-Framework auf. Konfuziuskonzipiert für komplexe, mehrstufige Denkaufgaben. Es bietet leistungsstarke Funktionen zur Codegenerierung und ein flexibles SDK für die Integration in die internen Toolsysteme von Meta, einschließlich Jobplanern, Infrastruktur zur Experimentverfolgung und Codebasis-Navigationstools.
Hochwertige, vielfältige Hypothesengenerierung
Die Qualität der Hypothese bestimmt direkt die Qualität eines ML-Experiments. REA nutzt zwei spezialisierte Systeme, um vielfältige und qualitativ hochwertige Ideen zu generieren:
- Datenbank für historische Erkenntnisse: Ein kuratiertes Repository vergangener Experimente, das kontextbezogenes Lernen und Mustererkennung über frühere Erfolge und Misserfolge hinweg ermöglicht.
- ML-Forschungsagent: Eine umfassende Forschungskomponente, die grundlegende Modellkonfigurationen untersucht und mithilfe der Meta-Datenbank mit historischen Erkenntnissen neue Optimierungsstrategien vorschlägt.
Durch die Synthese von Erkenntnissen aus beiden Quellen werden REA-Konfigurationen sichtbar, die sich wahrscheinlich nicht aus einem einzelnen Ansatz isoliert ergeben. Die wirkungsvollsten Verbesserungen von REA haben Architekturoptimierungen mit Trainingseffizienztechniken kombiniert – ein Ergebnis dieser systemübergreifenden Methodik.
Belastbare Ausführung innerhalb realer Einschränkungen
Experimente in der realen Welt unterliegen Recheneinschränkungen und unvermeidlichen Fehlern. REA adressiert beides durch strukturierte Planung und autonome Anpassung.
Vor der Umsetzung eines Plans schlägt REA eine detaillierte Explorationsstrategie vor, schätzt die gesamten GPU-Rechenkosten und bestätigt den Ansatz mit einem Ingenieur. Ein typischer Mehrphasenplan durchläuft drei Phasen:
- Validierung: Einzelne Hypothesen aus verschiedenen Quellen werden parallel getestet, um Qualitätsgrundlagen zu ermitteln.
- Kombination: Vielversprechende Hypothesen werden kombiniert, um nach synergistischen Verbesserungen zu suchen.
- Ausbeutung (intensive Optimierung): Die vielversprechendsten Kandidaten werden intensiv untersucht, um die Ergebnisse innerhalb des genehmigten Rechenbudgets zu maximieren.
Wenn REA auf Ausfälle stößt – etwa Infrastrukturprobleme, unerwartete Fehler oder suboptimale Ergebnisse –, passt es den Plan innerhalb vordefinierter Leitlinien an, anstatt auf menschliches Eingreifen zu warten. Es konsultiert ein Runbook mit häufigen Fehlermustern, trifft Priorisierungsentscheidungen (z. B. den Ausschluss von Jobs mit eindeutigen Fehlern wegen unzureichendem Arbeitsspeicher oder Trainingsinstabilitätssignalen wie Verlustexplosionen) und behebt vorläufige Infrastrukturausfälle von Anfang an. Diese Belastbarkeit ist entscheidend für die Aufrechterhaltung der Autonomie bei langfristigen Aufgaben, bei denen Ingenieure eher eine regelmäßige Aufsicht als eine kontinuierliche Überwachung übernehmen.
REA arbeitet mit strengen Sicherheitsvorkehrungen. Es funktioniert ausschließlich auf der Codebasis des Anzeigenranking-Modells von Meta. Ingenieure gewähren explizite Zugriffskontrollen durch Überprüfungen von Checklisten vor dem Flug, und REA bestätigt Rechenbudgets im Voraus und stoppt oder pausiert Läufe, wenn Schwellenwerte erreicht werden.
Die REA-Systemarchitektur
![图片[1]-Ranking Engineer Agent (REA): The Autonomous AI Agent Accelerating Meta’s Ads Ranking Innovation For Windows 7,8,10,11-Winpcsoft.com](https://winpcsoft.com/wp-content/plugins/wp-fastest-cache-premium/pro/images/blank.gif)
Der Ranking Engineer Agent basiert auf zwei miteinander verbundenen Komponenten: REA-Planer Und REA-Vollstreckerunterstützt durch eine gemeinsame Fähigkeits-, Wissens- und Werkzeugsystem das ML-Funktionen, historische Experimentdaten und Integrationen mit der internen Infrastruktur von Meta bietet. Zusammen ermöglichen sie direkt die drei Kernfunktionen des Agenten.
Autonomie über einen langen Horizont wird durch den Ausführungsablauf unterstützt: Ein Ingenieur arbeitet mit dem Hypothesengenerator zusammen, um über den REA Planner einen detaillierten Experimentplan zu erstellen. Dieser Plan wird in den REA Executor exportiert, der die asynchrone Auftragsausführung über eine Agentenschleife und einen Wartezustand verwaltet, während der Trainingsläufe in einen Wartezustand wechselt und nach Abschluss mit Ergebnissen fortfährt, anstatt eine kontinuierliche menschliche Überwachung über mehrwöchige Arbeitsabläufe hinweg zu erfordern.
Hochwertige, vielfältige Hypothesengenerierung wird durch den Wissensfluss gesteuert: Während der Ausführende Experimente abschließt, zeichnet ein spezieller Experiment-Logger Ergebnisse, Schlüsselmetriken und Konfigurationen in einer zentralen Hypothesen-Experiment-Einblicksdatenbank auf. Dieser persistente Speicher sammelt Wissen über den gesamten Verlauf der Agentenoperationen. Der Hypothesengenerator nutzt diese Erkenntnisse, um Muster zu identifizieren, aus früheren Erfolgen und Misserfolgen zu lernen und für jede weitere Runde immer ausgefeiltere Hypothesen vorzuschlagen, wodurch der Kreis geschlossen und die Intelligenz des Systems im Laufe der Zeit verbessert wird.
Belastbare Ausführung wird über beide Abläufe hinweg aufrechterhalten: Wenn der Ausführende auf Ausfälle, Infrastrukturfehler, Signale wegen unzureichendem Arbeitsspeicher oder Trainingsinstabilität stößt, konsultiert er ein Runbook mit häufigen Fehlermustern und wendet eine Priorisierungslogik an, um sich innerhalb vordefinierter Leitplanken autonom anzupassen. Anschließend wird der Planer mit umsetzbaren Ergebnissen weitergeführt, anstatt den Ingenieuren routinemäßige Unterbrechungen aufzuzeigen.
Auswirkung: Modellgenauigkeit und technische Produktivität
Doppelte Modellgenauigkeit im Vergleich zu Basisansätzen
Bei der ersten Produktionsvalidierung über einen Satz von sechs Modellen verdoppelten REA-gesteuerte Iterationen die durchschnittliche Modellgenauigkeit im Vergleich zu Basisansätzen. Dies führt direkt zu besseren Ergebnissen für Werbetreibende und besseren Erlebnissen auf Meta-Plattformen.
5-fache Produktivitätssteigerung im Ingenieurwesen
REA verstärkt die Wirkung, indem es die Mechanismen des ML-Experimentes automatisiert und es Ingenieuren ermöglicht, sich auf kreative Problemlösungen und strategisches Denken zu konzentrieren. Komplexe Architekturverbesserungen, die zuvor mehrere Ingenieure über mehrere Wochen hinweg erforderten, können jetzt von kleineren Teams innerhalb weniger Tage abgeschlossen werden.
Frühanwender, die REA nutzen, erhöhten im gleichen Zeitraum ihre Vorschläge zur Modellverbesserung von eins auf fünf. Für die Arbeit, die früher zwei Ingenieure pro Modell erforderte, sind jetzt drei Ingenieure an acht Modellen erforderlich.
Die Zukunft der Mensch-KI-Zusammenarbeit im ML-Engineering
REA stellt einen Wandel in der Herangehensweise von Meta an ML-Engineering dar. Durch die Entwicklung von Agenten, die den gesamten Experimentierlebenszyklus autonom verwalten können, verändert das Team die Struktur der ML-Entwicklung und verlagert Ingenieure von der praktischen Durchführung von Experimenten hin zur strategischen Aufsicht, Hypothesenleitung und architektonischen Entscheidungsfindung.
Dieses neue Paradigma, bei dem Agenten iterative Mechanismen verwalten, während Menschen strategische Entscheidungen und endgültige Genehmigungen treffen, ist nur der Anfang. Datenschutz, Sicherheit und Governance bleiben für den Agenten oberste Priorität. Meta verbessert weiterhin die Fähigkeiten von REA, indem es spezielle Modelle für die Hypothesengenerierung verfeinert, Analysetools erweitert und den Ansatz auf neue Bereiche ausdehnt.
Danksagungen
Ashwin Kumar, Harpal Bassali, Shashank Ankit, Deepak Chandra, Chaorong Chen, Wenlin Chen, Vitor Cid, Peter Chu, Xiaoyu Deng, Jingyi Guan, Junhua Gu, Liquan Huang, Qinjin Jia, Santanu Kolay, Jakob Moberg, Shweta Memane, Jp Owed, Sandeep Pandey, Vijay Pappu, Shyam Rajaram, Ben Schulte, Jags Somadder, Matt Steiner, Ritwik Tewari, Hangjun Xu, Zhaodong Wang, Fan Yang, Xin Zhao, Zoe Zu