![Bild[1]-Stellen Sie Gemma bereit 4 auf Cloud Run: Zahlen Sie nur, wenn Sie es tatsächlich für Windows 7,8,10,11-Winpcsoft.com verwenden](https://winpcsoft.com/wp-content/plugins/wp-fastest-cache-premium/pro/images/blank.gif)
Ich war im Raum in Paris, als Google dies ankündigte Gemma 3. Es war eine aufregende Veranstaltung. Die Demos waren beeindruckend. Aber das wirklich Wichtige geschah später, zurück an meinem Schreibtisch, Als ich meine eigenen Tests durchführte und herausfand, dass die Demos nicht logen.
Gemma 3 war das erste offene Modell, das die Lücke zu den großen kommerziellen Modellen schloss. Es hat Gemini nicht geschlagen. Aber es erreichte das Niveau, das Gemini ein Jahr zuvor hatte. Ein offenes Modell könnten Sie auf Ihrer eigenen Infrastruktur ausführen, Das war ein bedeutungsvoller Sprung. Ich begann, es in meine eigenen Pipelines zu integrieren. Spezifische Aufgaben, kleine Schritte, Orte, an denen die Antwort kein Grenzmodell erfordert, um sie richtig zu finden.
Dann habe ich einen Fehler gemacht.
Ich habe Gemma eingesetzt 3 An Vertex AI Model Garden über ein Wochenende zum Testen. Habe es laufen lassen. Habe es nicht ausgeschaltet. Ich kam auf einen Gesetzentwurf zurück, der mich dazu brachte, meine Beziehung zur Cloud-Infrastruktur zu überdenken. Ich habe ein Video darüber gemacht mein YouTube-Kanal damit andere nicht den gleichen Fehler wiederholen.
Dieser Artikel ist die Erlösung.
Gemma 4 gerade gestartet. Es ist ein größerer Sprung als Gemma 3 War. Und dieses Mal, Ich stelle es bereit Cloud Run, die auf Null skaliert, wenn Sie sie nicht verwenden. Vergessen Sie, es auszuschalten. Du traust dich ja nicht. Sie zahlen keinen Cent.
Dieser Artikel besteht aus zwei Teilen. Der erste befasst sich mit Gemma 4 Ist, Warum die Ausführung Ihres eigenen Modells das verändert, was Sie erstellen können, wie der Bereitstellungsstapel funktioniert, und die Leistungsdaten aus meinen eigenen Tests.
Der zweite Teil ist die Schritt-für-Schritt-Anleitung zur Bereitstellung. Voraussetzungen, VPC-Setup, Modell-Upload, Bereitstellungsbefehle für alle vier Modellgrößen, und Aufräumen.
Teil 1: Gemma verstehen 4 auf Cloud Run
Was sich in Gemma geändert hat 4
Gemma 4 Wird in vier verschiedenen Modellen geliefert, nicht einer. Zwei kleine und zwei große, jedes mit einem anderen Kompromiss.
| Modell | Parameter | Architektur | Kontextfenster |
|---------|----------------------|--------------|----------------|
| E2B | 2.3B wirksam | Dicht | 128k Token |
| E4B | 4.5B wirksam | Dicht | 128k Token |
| 26B A4B | 26B insgesamt, 4B aktiv | MoE | 256k Token |
| 31B | 31B | Dicht | 256k Token |
Das Modell 26B verdient einen genaueren Blick. Es nutzt Mischung aus Experten (MoE) Architektur: ein Design, bei dem das Modell vorhanden ist 26 Milliarden Parameter auf der Festplatte, aber nur aktiviert 4 Milliarden davon pro Token während der Inferenz. Stellen Sie sich das wie ein großes Team von Spezialisten vor, bei dem für jede Aufgabe nur die relevanten Experten hinzugezogen werden, anstatt dass jeder an jedem Problem arbeitet. Das Ergebnis: Fähigkeit, die einem 26B-Modell nahekommt, zum Rechenaufwand eines 4B-Modells. Dies ist zum Zeitpunkt der Inferenz von enormer Bedeutung, wie Sie in den Zahlen unten sehen werden.
Über die Größe hinaus, Gemma 4 fügt hinzu multimodale Eingabe. Bilder, Audio-, Video: alle werden als Eingaben unterstützt, mit Textausgabe. Die kleinen Modelle (E2B, E4B) kann Video mit Audio verarbeiten. Die größeren verarbeiten Bilder mit erweitertem Kontext.
Aber die beiden Verbesserungen, die für jeden, der Agentenpipelines erstellt, am wichtigsten sind, sind: Argumentation Und Funktionsaufruf.
Argumentation bedeutet, dass das Modell ein Problem Schritt für Schritt durcharbeitet, bevor es eine Antwort liefert, anstatt direkt zu einer Antwort zu springen. Für komplexe Aufgaben, die bisher ein Grenzmodell erforderten, eine vernünftige Gemma 4 können sie nun zu einem Bruchteil der Kosten handhaben. Auch der Funktionsaufruf wurde deutlich verbessert, Das Modell gibt strukturierte Werkzeugaufrufe zuverlässig zurück, Dadurch ist es innerhalb eines Agenten zusammensetzbar, der mehrere Schritte orchestriert.
Zusammen, Diese beiden Fähigkeiten verändern die Position von Gemma in einem Produktionssystem. Meine eigenen Pipelines teilen die Arbeit in Schichten auf: klein, gezielte Schritte, die keiner tiefgreifenden Überlegung bedürfen, und Orchestrierungsschritte, die die Ergebnisse auswerten und entscheiden, was als nächstes passiert. Gemma 3 konnte mit den einfachen Schritten umgehen. Gemma 4 kann auch mehr von der Mittelschicht verarbeiten, Die Aufgaben, die zuvor eine größere Aufgabe erforderten, teureres Modell, um es richtig zu machen. Jeder Schritt, der von einer Frontier-API zu einem selbstgehosteten Gemma erfolgt, bedeutet Token, für die Sie nicht mehr bezahlen müssen.
Warum die Ausführung Ihres eigenen Modells Ihre Baumöglichkeiten verändert
Erste, Lassen Sie uns genau sagen, was „offen“ hier bedeutet. Gemma 4 ist kein Open Source. Der Trainingscode, die Trainingsdaten, und das vollständige Rezept, nach dem das Modell hergestellt wurde, sind nicht öffentlich. Was Google veröffentlicht, sind die Gewichte, die trainierten Parameter des Modells selbst, unter dem Apache 2.0 Lizenz. Sie können sie herunterladen, führe sie aus, modifizieren Sie sie, und darauf kommerzielle Produkte aufbauen. Aber Sie können den Trainingsprozess nicht reproduzieren.
Diese Unterscheidung ist für die meisten Anwendungsfälle weniger wichtig, als man denkt, und mehr, als die Leute für einen bestimmten Menschen denken: Feinabstimmung.
Weil du die Gewichte hast, Sie können darauf trainieren. Nehmen Sie das 4B-Modell, Führen Sie es durch Ihren eigenen domänenspezifischen Datensatz aus, und erstellen Sie eine Version, die Ihre Terminologie versteht, folgt Ihrem Ausgabeformat, und leistet bei Ihren spezifischen Aufgaben eine bessere Leistung als das Allzweckmodell. Dies ist der Weg vom „fähigen offenen Modell“ zum „Modell, das Ihr Unternehmen kennt“. Die Daten, die Sie zur Feinabstimmung verwenden, verlassen niemals Ihre Umgebung, und das Ergebnis gehört Ihnen.
Es gibt eine Kategorie von Problemen, die große, in der Cloud gehostete Modelle für bestimmte Kunden nicht lösen können. Nicht, weil die Modelle nicht dazu in der Lage wären, sondern weil die Daten das Gebäude nicht verlassen können.
Gesundheitsdienstleister, Finanzinstitute, Anwaltskanzleien. Organisationen mit schwerwiegenden Datenschutzverpflichtungen können vertrauliche Informationen nicht über externe APIs weiterleiten. Für sie, Leistungsstarke KI bedeutete schon immer, Daten der Infrastruktur eines anderen zugänglich zu machen. In vielen regulierten Umgebungen ist das kein Ansatzpunkt.
Ein selbst gehostetes Gemma auf Ihrem eigenen Cloud Run-Dienst ändert die Gleichung. Das Modell läuft in Ihrem Projekt, Ihre VPC, Ihre Infrastruktur. Die Daten gehen nie verloren.
Das überzeugendste Beispiel ist jedoch nicht das Büro. Es ist auf einem Feld.
Stellen Sie sich eine Drohne mit Kameras vor, die über Ackerland fliegt, Einsatz von Computer Vision und Argumentation zur Erkennung von Pflanzenkrankheiten, Bewässerungsprobleme identifizieren, oder Schädlingsschäden erkennen. Diese Drohne kann nicht auf einen Roundtrip-API-Aufruf an einen Cloud-Endpunkt warten. An einem abgelegenen Ort auf dem Land gibt es möglicherweise nicht einmal eine zuverlässige Internetverbindung. Die Entscheidung muss auf dem Gerät getroffen werden, oder in der Nähe davon. Und es muss schnell gehen.
Die multimodale Fähigkeit von Gemma 4, kombiniert mit seinen kleinen Modellgrößen, macht diese Art der On-Device- oder Edge-Bereitstellung praktisch. Ein 2B- oder 4B-Modell kann auf Hardware laufen, die eine Drohne oder ein Industriesensor realistischerweise tragen oder mit der sie verbunden werden könnte. Dank der Fähigkeit zum logischen Denken kann es mehr als nur klassifizieren. Es kann durchdenken, was es sieht.
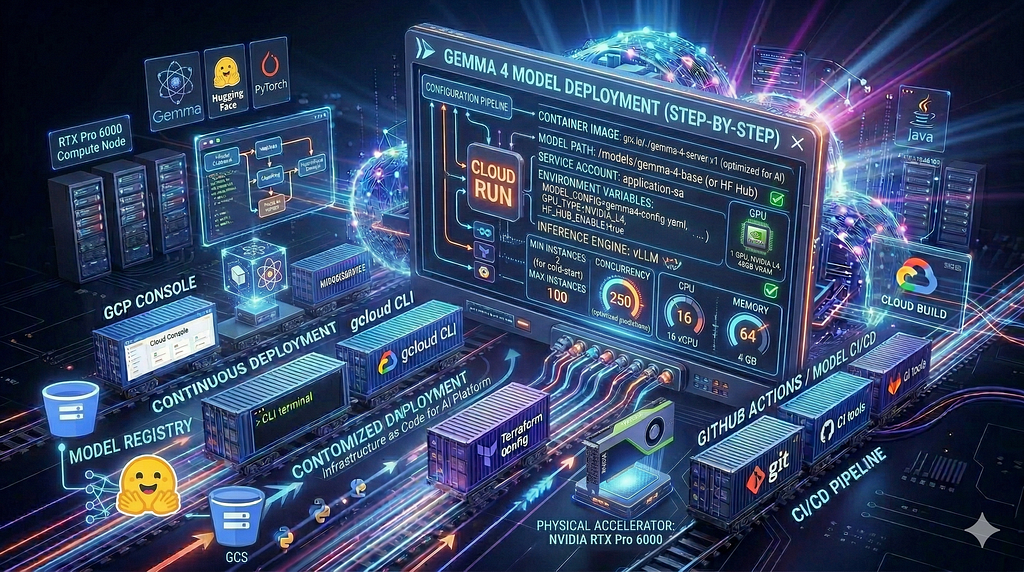
Wie Gemma 4 Wird bereitgestellt: Der Stapel
Als Gemma 3 kam heraus, die typische verwendete Bereitstellung Zu sein, Ein Tool zum lokalen Ausführen von Modellen. Es ist einfach, Funktioniert gut für kleine Modelle, und Sie können schnell etwas zum Laufen bringen. Ollama backt die Modellgewichte direkt in das Containerbild. Der Container startet, das Modell ist schon da, und Sie servieren in Sekundenschnelle. Für ein 2B- oder 7B-Modell ist das in Ordnung.
Die größeren Modelle von Gemma 4 durchbrechen dieses Muster. Ein 31B-Modell passt nicht bequem in ein Containerbild. Sie können nicht 65 GB an Gewichten in etwas integrieren, von dem Sie erwarten, dass es schnell bereitgestellt und skaliert wird. Außerdem stellt Ollama die Produktionskontrollen, die Sie benötigen, nicht im großen Maßstab zur Verfügung: Anforderungsstapelung, KV-Cache-Freigabe über gleichzeitige Anfragen hinweg, Quantisierung, die die Genauigkeit nicht beeinträchtigt. Es ist ein großartiges lokales Tool. Es ist nicht für das konzipiert, was wir hier bauen.
Der offizielle Pfad von Gemma 4 verwendet vLLM stattdessen. vLLM ist eine Inferenz-Engine, die speziell für die Bereitstellung von LLMs in der Produktion entwickelt wurde. Es verarbeitet mehrere gleichzeitige Anfragen effizient, indem es sie stapelt, teilt den KV-Cache für alle Anfragen, um den Speicherdruck zu reduzieren, und unterstützt die fp8-Quantisierung, Dadurch passt das Modell 31B in das NVIDIA RTX Pro 6000 Blackwell96 GB VRAM ohne nennenswerten Qualitätsverlust. Kein zu verwaltender Cluster, Kein zu konfigurierender Knotenpool. Ein Flag in Ihrem Bereitstellungsbefehl.
Für die Modelle 26B und 31B, Es gibt noch ein drittes Stück: Die Laufen:ai Model Streamer. Anstatt darauf zu warten, dass das gesamte Modell geladen ist, bevor die erste Anfrage bearbeitet wird, Der Streamer holt sich parallel Gewichte von Google Cloud-Speicher während vLLM initialisiert wird. Das Modell beginnt mit der Annahme von Anfragen, bevor es vollständig geladen ist. Dies macht Kaltstarts großer Modelle auf Cloud Run eher machbar als schmerzhaft.
Die Modellladeentscheidung: HuggingFace gegen GCS
Vor der Bereitstellung, Es gibt eine Wahl, die alles andere beeinflusst: Woher kommt das Modell beim Start??
Umarmendes Gesicht ist die einfache Möglichkeit. Der Container lädt die Modellgewichte bei jedem Kaltstart herunter. Keine Lagerkosten, Keine Vorab-Einrichtung. Der Kompromiss: Sie laden jedes Mal über das öffentliche Internet herunter, und diese Downloadzeit dominiert Ihren Kaltstart.
Google Cloud-Speicher ist die Produktionsoption. Sie laden die Gewichte einmalig hoch, und der Container streamt sie bei jedem Kaltstart über den Run von GCS:ai Model Streamer. Weitere Einrichtung im Voraus. Das Streaming erfolgt jedoch über das interne Netzwerk von Google, und der Geschwindigkeitsunterschied ist erheblich.
Hier ist der Teil, der mich überrascht hat, als ich es getestet habe: GCS ohne ordnungsgemäße VPC-Konfiguration ist tatsächlich Langsamer als HuggingFace für kleine Modelle. Der Lauf:Der Vorteil eines AI-Streamers stellt sich nur dann ein, wenn der Datenverkehr im internen Netzwerk von Google verbleibt. Wenn es ins öffentliche Internet geht, Der Mehraufwand macht den Nutzen zunichte.
Die Lösung ist Privater Google-Zugriff in Ihrem VPC-Subnetz. Ein Befehl. Es öffnet eine Route von Ihrem Cloud Run-Container zu Google APIs (einschließlich GCS) ohne das öffentliche Internet zu berühren. In der offiziellen Dokumentation wird dies nicht hervorgehoben, und es ist das wichtigste Detail in diesem gesamten Leitfaden.
Die Zahlen
Ich habe alle vier Modellgrößen von HuggingFace und von GCS eingesetzt, mit und ohne VPC, und gemessene Kaltstartzeit (erste Anfrage nach der Skalierung auf Null), Zeit bis zum ersten Token, und warme Reaktionszeit. Jedes Mal die gleiche Aufforderung: „Was ist der Mond??”
Eine Anmerkung zur Methodik: es handelt sich um Einzelmessungen, keine Durchschnittswerte aus einer vollständigen Benchmark-Suite. LLMs sind von Natur aus nichtdeterministisch, und die Leistung der Infrastruktur variiert je nach Last, Kapazität der Region, und Netzwerkbedingungen. Die Zahlen unten sind richtungsrichtig, nicht wissenschaftlich präzise. Verwenden Sie sie, um die relativen Kompromisse zwischen Bereitstellungsoptionen zu verstehen. Bevor Sie sich auf einen Ansatz in der Produktion festlegen, Führen Sie Ihre eigenen Tests mit Ihrem eigenen Arbeitsaufwand durch.
| Modell | Quelle | Kaltstart | Herzliche Antwort |
|-------|--------------|------------|---------------|
| 2B | Umarmendes Gesicht | 311S | 1.75S |
| 2B | GCS (kein VPC) | 334S | 1.81S |
| 2B | GCS + VPC | **245S** | 1.81S |
| 4B | Umarmendes Gesicht | 452S | 2.46S |
| 4B | GCS (kein VPC) | 433S | 2.47S |
| 4B | GCS + VPC | **246S** | 2.47S |
| 26B | GCS + VPC | **191S** | 1.61S |
| 31B | GCS + VPC | **251S** | 5.90S |
Ein paar Dinge zum Auspacken.
GCS ohne VPC ist für kleine Modelle langsamer als HuggingFace. Der Streamer verursacht einen Overhead, der sich nur bei schnellem Datenverkehr auszahlt. Über das öffentliche Internet, HuggingFace gewinnt für kleine Dateien.
VPC verändert alles. Mit privatem Google-Zugriff, der 4B Kaltstart fällt ab 433 Sekunden zu 246 Sekunden. Das ist ein 43% Reduzierung allein durch eine andere Weiterleitung des Datenverkehrs.
Das 26B-Modell startet schneller kalt als das 2B von HuggingFace. Lesen Sie das noch einmal. A 26 Milliarden-Parameter-Modell, über das interne Netzwerk von Google gestreamt, ist bereit zum Servieren 191 Sekunden. Das Herunterladen von HuggingFace dauert 2B 311 Sekunden. Netzwerkpfad und Streaming-Architektur sind wichtiger als die Modellgröße auf der Festplatte.
MoE vs. dichte Materie zur Inferenzzeit, nicht nur Startup. Die 26B-Warmreaktion ist 1.61 Sekunden. Die 31B ist 5.90 Sekunden. Der 31B ist ein dichtes Modell: jedes einzelne davon 31 An jedem Token sind Milliarden Parameter beteiligt. Der 26B aktiviert nur 4 Milliarden auf einmal. Aus diesem Grund reagiert der 26B fast viermal schneller, obwohl er nominell „größer“ ist. Für latenzempfindliche Anwendungen mit einer Kontextanforderung von 256 KB, der 26B A4B ist die interessantere Wahl.
Scale-to-Zero und was es für die Kosten bedeutet
Cloud Run skaliert laufende Instanzen basierend auf dem Datenverkehr. Wenn keine Anfragen vorliegen, es skaliert auf Null. Keine Instanzen, Keine GPU zugewiesen, keine Kosten. Der Moment, in dem eine Anfrage eintrifft, Eine neue Instanz wird gestartet, lädt das Modell, und serviert es.
Dies unterscheidet sich grundlegend von Vertex AI Model Garden, Dabei hält ein bereitgestellter Endpunkt eine laufende Instanz am Leben. Gehen Sie übers Wochenende weg, Kommen wir zurück zu einer Rechnung.
Mit der Skalierung auf Null von Cloud Run, Der schlimmste Fall ist die Kaltstartverzögerung. Und wie die Zahlen zeigen, selbst ein 26B-Modell ist in etwa drei Minuten fertig. Zum Entwickeln und Testen, Dieser Kompromiss ist unkompliziert.
Um zu überprüfen, ob eine Instanz auf Null skaliert wurde: Öffnen Sie die Cloud Run-Konsole, Klicken Sie auf Ihren Dienst, geh zum Metriken Tab, und anschauen Anzahl der Instanzen. Null bedeutet, dass Ihnen keine Kosten berechnet werden. Oder einfach warten 5 Minuten nach Ihrer letzten Anfrage und senden Sie eine neue. Wenn es dauert 200+ Sekunden statt 2, Die Instanz wurde verkleinert.
Scale-to-Zero ist die richtige Wahl für Entwicklung und Tests. Aber es ist nicht die einzige Option. Mit Cloud Run können Sie auch eine festlegen Mindestanzahl an Instanzen um jederzeit am Leben zu bleiben. Für die Produktion mit gleichmäßigem Datenverkehr, Sie würden mindestens eine Warminstanz konfigurieren, um Kaltstarts vollständig zu verhindern. Das verändert das Kostenmodell, Sie zahlen wieder für Leerlaufzeit, aber es ist ein bewusster Kompromiss, kein Unfall.
Die Anleitung in diesem Artikel ist zum Testen optimiert: minimale Kosten, maximale Flexibilität, Alles auf Null skalieren. Wenn Sie bereit sind, in die Produktion überzugehen und über Mindestinstanzen nachdenken müssen, Parallelitätsoptimierung, und Verkehrsmanagement, mein Beitrag „Das ist Cloud Run: Konfiguration" deckt diese Optionen ab.
Teil 2: Der Bereitstellungsleitfaden
Ich habe das alles selbst durchgearbeitet, bevor ich ein Wort dieses Leitfadens geschrieben habe. Wird in jeder Modellgröße eingesetzt, jeden Fehler treffen, jeden Fehler behoben. Die folgenden Anweisungen funktionieren bei mir tatsächlich.
Was Sie brauchen
- Ein Google Cloud-Projekt mit aktivierter Abrechnung
- Cloud Shell (empfohlen) oder die gcloud-CLI lokal installiert. This guide assumes you're using Cloud Shell.
- Zugang zur Gemma 4 Modelle auf Umarmendes Gesicht (erfordert das Akzeptieren der Lizenz für jedes Modell)
- A HuggingFace-Zugriffstoken mit Lesezugriff
Ich habe alles unten ausgeführt Cloud Shell. Das browserbasierte Terminal von Google Cloud, Vorauthentifiziert mit Ihrem Konto und bereits installiertem gcloud. Keine lokale Einrichtung, Keine Versionskonflikte. Öffnen Sie es über die Cloud Console, indem Sie oben rechts auf das Terminalsymbol klicken.
Schritt 1: Legen Sie Ihre Umgebungsvariablen fest
Legen Sie diese einmalig zu Beginn Ihrer Cloud Shell-Sitzung fest. Jeder Befehl in diesem Handbuch verwendet sie:
export GOOGLE_CLOUD_PROJECT="your-project-id"
export GOOGLE_CLOUD_REGION="us-central1"
export GCS_BUCKET="${GOOGLE_CLOUD_PROJECT}-Modell-Cache"
export VPC_NETWORK="gemma-vpc"
export VPC_SUBNET="gemma-subnet"
export HF_TOKEN="your-huggingface-token"
export PROJECT_NUMBER=$(gcloud projects describe "${GOOGLE_CLOUD_PROJECT}" \
--format='value(Projektnummer)')
Notiz 1: RTX Pro 6000 Verfügbar in den Regionen USA-Zentral1 und Europa-West4
Notiz 2: Bei Cloud Shell-Sitzungen bleiben Umgebungsvariablen bei erneuten Verbindungen nicht erhalten. Wenn Sie Cloud Shell schließen und erneut öffnen, Führen Sie diesen Block erneut aus, bevor Sie fortfahren.
Schritt 2: Aktivieren Sie die erforderlichen APIs
An einem neuen Projekt, Sie werden all das brauchen:
gcloud-Dienste aktivieren \
run.googleapis.com \
compute.googleapis.com \
storage.googleapis.com \
artefaktregistry.googleapis.com \
iam.googleapis.com \
--Projekt $GOOGLE_CLOUD_PROJECT
compute.googleapis.com ist für VPC- und GPU-Ressourcen erforderlich. iam.googleapis.com ist erforderlich, um dem Cloud Run-Dienstagenten Berechtigungen zu erteilen. Die anderen decken den Modellspeicher und Cloud Run selbst ab.
Schritt 3: Überprüfen Sie das GPU-Kontingent (optional)
Für den Cloud Run-GPU-Zugriff ist eine Kontingentgenehmigung erforderlich. Sie können Ihre aktuelle Zuteilung überprüfen:
Gehe zu ICH BIN & Admin > Quoten & Systemgrenzen im Google Cloud Console, Filtern Sie nach NVIDIA_RTX_PRO_6000 und Region:us-central1. Wenn das Limit ist 0 or the quota doesn't appear, Sie müssen es anfordern.
Fordern Sie ein GPU-Kontingent über an Seite „Cloud Run-Kontingente“.. Die Genehmigung erfolgt nicht sofort, ein paar Tage einplanen.
Schritt 4: Erstellen Sie die VPC
Wie im Teil erläutert 1, Der private Google-Zugriff auf das Subnetz ist der entscheidende Schritt. Ohne es, Der Container kann GCS überhaupt nicht erreichen. Es ist direkt im unten aufgeführten Befehl zum Erstellen von Subnetzen enthalten – es ist kein separates Update erforderlich.
gcloud compute networks create "${VPC_NETWORK}" \
--Subnetzmodus=benutzerdefiniert \
--bgp-routing-mode=regional \
--project="${GOOGLE_CLOUD_PROJECT}"
gcloud compute networks subnets create "${VPC_SUBNET}" \
--network="${VPC_NETWORK}" \
--region="${GOOGLE_CLOUD_REGION}" \
--Bereich=10.0.0.0/24 \
--Aktivieren Sie den privaten IP-Google-Zugriff \
--project="${GOOGLE_CLOUD_PROJECT}"
Erteilen Sie dem Cloud Run-Dienstagenten die Berechtigung, das Subnetz zu verwenden:
gcloud projects add-iam-policy-binding "${GOOGLE_CLOUD_PROJECT}" \
--member="serviceAccount:Service-${PROJECT_NUMBER}@serverless-robot-prod.iam.gserviceaccount.com" \
--role="roles/compute.networkUser"
Notiz: In Produktion, anstatt das Standard-Rechendienstkonto zu verwenden, Erstellen Sie einen dedizierten Bucket mit dem geringsten Zugriff auf den GCS-Bucket.
Schritt 5: Erstellen Sie den GCS-Bucket und laden Sie Modelle hoch
Erstellen Sie einen Single-Region-Bucket in derselben Region wie Ihr Cloud Run-Dienst:
gcloud storage buckets create "gs://${GCS_BUCKET}" \
--location="${GOOGLE_CLOUD_REGION}" \
--einheitlicher Zugang auf Eimerebene \
--project="${GOOGLE_CLOUD_PROJECT}"
gcloud storage buckets add-iam-policy-binding "gs://${GCS_BUCKET}" \
--member="serviceAccount:${PROJECT_NUMBER}[email protected]" \
--role="roles/storage.objectViewer"
Auf Speicherplatz: Der 2B (~5GB) und 4B (~9GB) Modelle passen in Cloud Shell. Der 26B (~50 GB) und 31B (~65GB) nicht. Cloud Shell verfügt über etwa 5 GB Festplatte. Für die großen Modelle, Starten Sie eine temporäre GCE-VM:
gcloud-Compute-Instanzen erstellen einen Gemma-Uploader \
--project="${GOOGLE_CLOUD_PROJECT}" \
--zone="${GOOGLE_CLOUD_REGION}-A" \
--Maschinentyp=n2-standard-8 \
--Boot-Disk-Größe = 300 GB \
--boot-disk-type=pd-ssd \
--image-family=debian-12 \
--image-project=debian-cloud \
--Netzwerk=Standard \
--Subnetz=Standard \
--Bereiche=Speicher voll
Wenn Sie einen Subnetzfehler erhalten, Versuchen Sie es mit der Einstellung –network="${VPC_NETWORK}" –subnet="${VPC_SUBNET}"
gcloud compute ssh gemma-uploader \
--project="${GOOGLE_CLOUD_PROJECT}" \
--zone="${GOOGLE_CLOUD_REGION}-A" \
--network="${VPC_NETWORK}" \
--subnet="${VPC_SUBNET}"
Innerhalb der VM, Installieren Sie Abhängigkeiten und laden Sie die Modelle hoch:
export HF_TOKEN="your-huggingface-token"
export GCS_BUCKET="your-bucket-name"
Sudo apt-get update && sudo apt-get install -y python3-pip --fix-missing
python3 -m pip install Huggingface_hub hf_transfer --break-system-packages
# Stoppen Sie sofort, wenn ein Schritt fehlschlägt
set -e
# Herunterladen, hochladen, und bereinigen Sie jedes Modell einzeln
for MODEL in "google/gemma-4-E2B-it:gemma-4-E2B-it" \
"google/gemma-4-E4B-it:gemma-4-E4B-it" \
"google/gemma-4-26B-A4B-it:gemma-4-26B-A4B-it" \
"google/gemma-4-31B-it:gemma-4-31B-it"; Tun
REPO="${MODELL%%:*}"
DIR="${MODELL##*:}"
export HF_HOME="/tmp/hf_cache_${DIR}"
python3 -c "
von Huggingface_hub Snapshot_Download importieren
Betriebssystem importieren
snapshot_download(repo_id='${REPO}', local_dir='/tmp/${DIR}', token=os.environ['HF_TOKEN'])
"
gcloud storage cp /tmp/${DIR}/* "gs://${GCS_BUCKET}/Modelle/${DIR}/" --rekursiv
rm -rf /tmp/${DIR} "/tmp/hf_cache_${DIR}"
Erledigt
Beenden Sie die VM und löschen Sie sie:
Ausfahrt
gcloud-Compute-Instanzen löschen den Gemma-Uploader \
--project="${GOOGLE_CLOUD_PROJECT}" \
--zone="${GOOGLE_CLOUD_REGION}-A" \
--ruhig
Schritt 6: Einsetzen
Jede Bereitstellung verwendet dasselbe vorgefertigte Container-Image von Google:
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:gemma4
Ein wichtiges Detail, das in Teil behandelt wird 1: Der Container liest die Modell- oder vLLM-Flags nicht aus Umgebungsvariablen. Sie müssen überquert werden –command="vllm" Und –args. Ohne –command="vllm", Das Startskript schlägt sofort fehl.
2B-Modell:
export GCS_MODEL_PATH_2B="gs://${GCS_BUCKET}/models/gemma-4-E2B-it"
gcloud-Betalaufbereitstellung gemma4-2b \
--image="us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:gemma4" \
--project="${GOOGLE_CLOUD_PROJECT}" \
--region="${GOOGLE_CLOUD_REGION}" \
--Ausführungsumgebung=gen2 \
--erlauben-nicht authentifiziert \
--CPU=20 \
--Speicher=80Gi \
--GPU=1 \
--GPU-Typ=nvidia-rtx-pro-6000 \
--Keine GPU-Zonenredundanz \
--Keine CPU-Drosselung \
--max-instanzen=1 \
--Parallelität=64 \
--Zeitüberschreitung = 600 \
--network="${VPC_NETWORK}" \
--subnet="${VPC_SUBNET}" \
--vpc-egress=all-traffic \
--command="vllm" \
--args="serve,${GCS_MODEL_PATH_2B},--enable-chunked-prefill,--Präfix-Caching aktivieren,--generation-config=auto,--Automatische Werkzeugauswahl aktivieren,--tool-call-parser=gemma4,--reasoning-parser=gemma4,--dtype=bfloat16,--max-num-seqs=64,--gpu-memory-utilization=0.95,--load-format=runai_streamer,--tensor-parallel-size=1,--port=8080,--host=0.0.0.0" \
--startup-probe="tcpSocket.port=8080,initialDelaySeconds=60,failureThreshold=5,timeoutSeconds=60,periodSeconds=60"
4B-Modell: gleichen Befehl, Ersetzen Sie GCS_MODEL_PATH_2B durch GCS_MODEL_PATH_4B, Dienstname mit gemma4-4b.
export GCS_MODEL_PATH_4B="gs://${GCS_BUCKET}/models/gemma-4-E4B-it"
gcloud-Betalaufbereitstellung gemma4-4b \
--image="us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:gemma4" \
--project="${GOOGLE_CLOUD_PROJECT}" \
--region="${GOOGLE_CLOUD_REGION}" \
--Ausführungsumgebung=gen2 \
--erlauben-nicht authentifiziert \
--CPU=20 \
--Speicher=80Gi \
--GPU=1 \
--GPU-Typ=nvidia-rtx-pro-6000 \
--Keine GPU-Zonenredundanz \
--Keine CPU-Drosselung \
--max-instanzen=1 \
--Parallelität=64 \
--Zeitüberschreitung = 600 \
--network="${VPC_NETWORK}" \
--subnet="${VPC_SUBNET}" \
--vpc-egress=all-traffic \
--command="vllm" \
--args="serve,${GCS_MODEL_PATH_4B},--enable-chunked-prefill,--Präfix-Caching aktivieren,--generation-config=auto,--Automatische Werkzeugauswahl aktivieren,--tool-call-parser=gemma4,--reasoning-parser=gemma4,--dtype=bfloat16,--max-num-seqs=64,--gpu-memory-utilization=0.95,--load-format=runai_streamer,--tensor-parallel-size=1,--port=8080,--host=0.0.0.0" \
--startup-probe="tcpSocket.port=8080,initialDelaySeconds=60,failureThreshold=5,timeoutSeconds=60,periodSeconds=60"
26B-Modell: Fügt die FP8-Quantisierung hinzu und verringert die Parallelität 8.
Die folgende Startprobe ermöglicht dies 6 Minuten insgesamt (1 Minute anfängliche Verzögerung + 5 Schecks × 1 jeweils eine Minute), basierend auf meiner gemessenen Ladezeit. Wenn bei Ihrer Bereitstellung eine Zeitüberschreitung auftritt, Erhöhen Sie den FailureThreshold – jede Einheit fügt eine weitere Minute hinzu:
export GCS_MODEL_PATH_26B="gs://${GCS_BUCKET}/models/gemma-4-26B-A4B-it"
gcloud-Betalaufbereitstellung gemma4-26b \
--image="us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:gemma4" \
--project="${GOOGLE_CLOUD_PROJECT}" \
--region="${GOOGLE_CLOUD_REGION}" \
--Ausführungsumgebung=gen2 \
--erlauben-nicht authentifiziert \
--CPU=20 \
--Speicher=80Gi \
--GPU=1 \
--GPU-Typ=nvidia-rtx-pro-6000 \
--Keine GPU-Zonenredundanz \
--Keine CPU-Drosselung \
--max-instanzen=1 \
--Parallelität=8 \
--Zeitüberschreitung = 600 \
--network="${VPC_NETWORK}" \
--subnet="${VPC_SUBNET}" \
--vpc-egress=all-traffic \
--command="vllm" \
--args="serve,${GCS_MODEL_PATH_26B},--enable-chunked-prefill,--Präfix-Caching aktivieren,--generation-config=auto,--Automatische Werkzeugauswahl aktivieren,--tool-call-parser=gemma4,--reasoning-parser=gemma4,--dtype=bfloat16,--quantization=fp8,--kv-cache-dtype=fp8,--max-num-seqs=8,--gpu-memory-utilization=0.95,--load-format=runai_streamer,--tensor-parallel-size=1,--port=8080,--host=0.0.0.0,--max-model-len=32767" \
--startup-probe="tcpSocket.port=8080,initialDelaySeconds=60,failureThreshold=5,timeoutSeconds=60,periodSeconds=60"
31B-Modell: wie 26B mit failThreshold=6, erlauben 7 Minuten insgesamt basierend auf meiner gemessenen Ladezeit. Erhöhen Sie bei Bedarf den FailureThreshold, Es gilt die gleiche Regel: Jede Einheit fügt eine Minute hinzu:
export GCS_MODEL_PATH_31B="gs://${GCS_BUCKET}/models/gemma-4-31B-it"
gcloud-Betalaufbereitstellung gemma4-31b \
--image="us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:gemma4" \
--project="${GOOGLE_CLOUD_PROJECT}" \
--region="${GOOGLE_CLOUD_REGION}" \
--Ausführungsumgebung=gen2 \
--erlauben-nicht authentifiziert \
--CPU=20 \
--Speicher=80Gi \
--GPU=1 \
--GPU-Typ=nvidia-rtx-pro-6000 \
--Keine GPU-Zonenredundanz \
--Keine CPU-Drosselung \
--max-instanzen=1 \
--Parallelität=8 \
--Zeitüberschreitung = 600 \
--network="${VPC_NETWORK}" \
--subnet="${VPC_SUBNET}" \
--vpc-egress=all-traffic \
--command="vllm" \
--args="serve,${GCS_MODEL_PATH_31B},--enable-chunked-prefill,--Präfix-Caching aktivieren,--generation-config=auto,--Automatische Werkzeugauswahl aktivieren,--tool-call-parser=gemma4,--reasoning-parser=gemma4,--dtype=bfloat16,--quantization=fp8,--kv-cache-dtype=fp8,--max-num-seqs=8,--gpu-memory-utilization=0.95,--load-format=runai_streamer,--tensor-parallel-size=1,--port=8080,--host=0.0.0.0,--max-model-len=32767" \
--startup-probe="tcpSocket.port=8080,initialDelaySeconds=60,failureThreshold=6,timeoutSeconds=60,periodSeconds=60"
Rufen Sie die Dienst-URLs nach der Bereitstellung ab:
export SERVICE_URL_2B=$(gcloud-Ausführungsdienste beschreiben gemma4-2b \
--region="${GOOGLE_CLOUD_REGION}" \
--project="${GOOGLE_CLOUD_PROJECT}" \
--format="value(status.url)")
export SERVICE_URL_4B=$(gcloud-Ausführungsdienste beschreiben gemma4-4b \
--region="${GOOGLE_CLOUD_REGION}" \
--project="${GOOGLE_CLOUD_PROJECT}" \
--format="value(status.url)")
export SERVICE_URL_26B=$(gcloud-Ausführungsdienste beschreiben gemma4-26b \
--region="${GOOGLE_CLOUD_REGION}" \
--project="${GOOGLE_CLOUD_PROJECT}" \
--format="value(status.url)")
export SERVICE_URL_31B=$(gcloud-Ausführungsdienste beschreiben gemma4-31b \
--region="${GOOGLE_CLOUD_REGION}" \
--project="${GOOGLE_CLOUD_PROJECT}" \
--format="value(status.url)")
echo "2B: $SERVICE_URL_2B"
echo "4B: $SERVICE_URL_4B"
echo "26B: $SERVICE_URL_26B"
echo "31B: $SERVICE_URL_31B"
Schritt 7: Testen Sie es
Der Dienst stellt eine bereit OpenAI-kompatible API. Jeder Client, der das OpenAI-Protokoll beherrscht, arbeitet dagegen.
Die erste Anfrage wird langsam sein. Wenn die Instanz auf Null skaliert wurde, Cloud Run muss ein neues starten und das Modell laden, bevor es reagiert. Für die 2B- und 4B-Modelle ist mit ca. zu rechnen 4 Minuten. Für 26B und 31B, bis zu 5 Minuten. Stornieren Sie die Anfrage nicht – sie wird zurückkommen. Jede weitere Anfrage wird schnell bearbeitet.
curl -X POST "${SERVICE_URL_2B}/v1/chat/completions" \
-H "Content-Type: application/json" \
-d '{
"model": "google/gemma-4-E2B-it",
"messages": [{"role": "user", "content": "What is the moon?"}],
"max_tokens": 200
}'
Der Modellname in der Anfrage muss mit der übergebenen HuggingFace-Repo-ID übereinstimmen –args (oder ein Brauch –servierter-Modellname, falls Sie einen festlegen).
Produktionshärten
Alles oben Genannte nutzt –Allow-unauthenticated und das Standard-Rechendienstkonto. That's fine for testing. Vor echten Benutzern oder echten Daten:
Authentifizierung. Ersetzen –erlauben-unauthentifiziert mit –no-allow-unauthenticated. Cloud Run unterstützt OIDC-Token für Service-zu-Service-Anrufe und IAP für den benutzerseitigen Zugriff.
Dediziertes Dienstkonto. Erstellen Sie einen mit nur „roles/storage.objectViewer“ für den Modell-Bucket. Das Standard-Rechendienstkonto verfügt über umfassendere Berechtigungen als erforderlich.
Privater Endpunkt. Für sensible Arbeitslasten, Entfernen Sie die öffentliche URL und greifen Sie nur über Ihre VPC auf den Dienst zu Cloud Run-Ingress-Einstellungen.
Aufräumen
Um alles zu entfernen, nachdem der Test abgeschlossen ist, Führen Sie diese Befehle der Reihe nach aus:
Löschen Sie die Cloud Run-Dienste:
für SERVICE in gemma4-2b gemma4-4b gemma4-26b gemma4-31b; Tun
gcloud führt Dienste aus und löscht $SERVICE \
--region="${GOOGLE_CLOUD_REGION}" \
--project="${GOOGLE_CLOUD_PROJECT}" \
--ruhig
Erledigt
Löschen Sie den GCS-Bucket und alle Modellgewichtungen:
gcloud storage rm -r "gs://${GCS_BUCKET}" Löschen Sie das VPC-Subnetz und -Netzwerk:
gcloud compute networks subnets delete "${VPC_SUBNET}" \
--region="${GOOGLE_CLOUD_REGION}" \
--project="${GOOGLE_CLOUD_PROJECT}" \
--ruhig
gcloud compute networks delete "${VPC_NETWORK}" \
--project="${GOOGLE_CLOUD_PROJECT}" \
--ruhig
Wenn das Löschen des Subnetzes fehlschlägt und ein Fehler bezüglich der noch verwendeten IP-Adressen auftritt: Cloud Run behält interne IP-Adressen für einen bestimmten Zeitraum bei, nachdem die Dienste gelöscht wurden. Nichts, was sie zwangsweise freilassen könnte. Nehmen Sie sich ein paar Stunden Zeit und versuchen Sie es erneut.
Entfernen Sie die IAM-Bindung:
gcloud projects remove-iam-policy-binding "${GOOGLE_CLOUD_PROJECT}" \
--member="serviceAccount:Service-${PROJECT_NUMBER}@serverless-robot-prod.iam.gserviceaccount.com" \
--role="roles/compute.networkUser"
Das größere Bild
Ich habe diesen Artikel mit einem Gespräch über einen Paris-Besuch und eine unerwartete Cloud-Rechnung begonnen. Aber der wahre Grund, warum ich Zeit damit verbracht habe, Gemma zu holen 4 Beim Laufen auf Cloud Run geht es nicht nur um die Kosten.
Es ist der Zugang.
Wenn ein LLM in Ihrer eigenen Infrastruktur läuft, Dinge werden möglich, die vorher nicht möglich waren. Regulierte Daten, die mit einer Drittanbieter-API nicht in Berührung kommen konnten, können jetzt von einem leistungsfähigen Modell verarbeitet werden. Privatsphäre wird zu einem Merkmal der Architektur, kein Kompromiss gegenüber der Leistungsfähigkeit.
Aber es gibt auch ein praktischeres Argument. Kommerzielle Grenzmodelle sind pro Token teuer, Außerdem gibt es regionale Tarifbegrenzungen, die Ihre Möglichkeiten begrenzen. Wenn Ihre Produktionspipeline eine Geschwindigkeitsbegrenzung erreicht, es wird es verlangsamen. Wenn Sie Ihr eigenes Modell treffen, Es gibt keine Tarifbegrenzung. Sie kontrollieren die Kapazität. Sie kontrollieren die Kosten. Sie entscheiden, wann Sie skalieren möchten.
Gemma 4 ist das erste offene Modell, bei dem dieser Kompromiss für das gesamte Spektrum der KI-Aufgaben wirklich Sinn macht: Text, Vision, Argumentation, Funktionsaufruf. Nicht jeder Schritt in Ihrer Pipeline benötigt ein Grenzmodell. Die Schritte, die das nicht tun, und mit der Denkfähigkeit von Gemma 4, Das sind mehr Schritte als zuvor, kann auf Ihrer eigenen Infrastruktur ausgeführt werden, zu einem Preis, den Sie kontrollieren, ohne dass eine Tarifbegrenzung in Sicht ist.
Die Drohne fliegt über die Felder des Bauern, selbstständig Entscheidungen treffen, ist keine Hypothese. Das Einzige, was fehlte, war ein Modell, das gut genug war, um mit Hardware zu laufen, die in einen Rucksack passt.
Jetzt gibt es einen. Und Sie wissen, wie man es einsetzt. Viel Spaß beim Entdecken.
![]()
Stellen Sie Gemma bereit 4 auf Cloud Run: Zahlen Sie nur, wenn Sie es tatsächlich nutzen. Es wurde ursprünglich in Google Developer Experts auf Medium veröffentlicht, wo die Leute das Gespräch fortsetzen, indem sie diese Geschichte hervorheben und darauf reagieren.