Ausführen großer Sprachmodelle (LLMs) auf mobilen Geräten war früher Zukunftsmusik. Heute, mit der Veröffentlichung von Google Gemma 4 Familie und die Mächtigen LiteRT-LM Rahmen, Höchstleistungen erbringen, multimodale Modelle direkt aufs Smartphone ist nicht nur möglich, aber auch äußerst effizient.
In diesem Beitrag, Wir erkunden die architektonischen Sprünge in Gemma 4, wie LiteRT-LM die Inferenz auf dem Gerät orchestriert, die Rolle von Qualcomms QNN für die NPU-Beschleunigung, und die praktischen technischen Änderungen, die erforderlich sind, um eine produktionsreife Android-Anwendung für ein 2,58-GB-KI-Modell zu erstellen.
Die Gemma 4 Architektur
Gemma von Google 4 stellt einen bedeutenden Sprung für Open-Weight-Edge-Modelle dar Gemma 4 E2B (Effektive ~2 Milliarden Parameter) Das Modell ist speziell auf mobile und Edge-Umgebungen zugeschnitten und bringt mehrere wichtige Innovationen mit sich:
- Native Multimodalität: Im Gegensatz zu früheren Iterationen, die nur Text enthielten, Gemma 4 versteht Text von Natur aus, Bilder und Audio. Es verwendet einen Vision-Encoder mit variablem Seitenverhältnis, der es ihm ermöglicht, Bilder mit unterschiedlichen Auflösungen zu verarbeiten, ohne den Kontext zu beeinträchtigen.
- Einbettungen pro Ebene (Bitte): Diese Technik reduziert den Speicherbedarf von Einbettungen, Dies ist für Geräte mit gemeinsam genutzter RAM-Architektur wie Android-Telefone von entscheidender Bedeutung.
- Gemeinsamer KV-Cache: Verbessert die Effizienz des Kontextmanagements, So kann das Modell problemlos bis zu einem Jahr bewältigen 32K-Token-Kontextfenster bei gleichzeitiger Minimierung von Speicherspitzen.
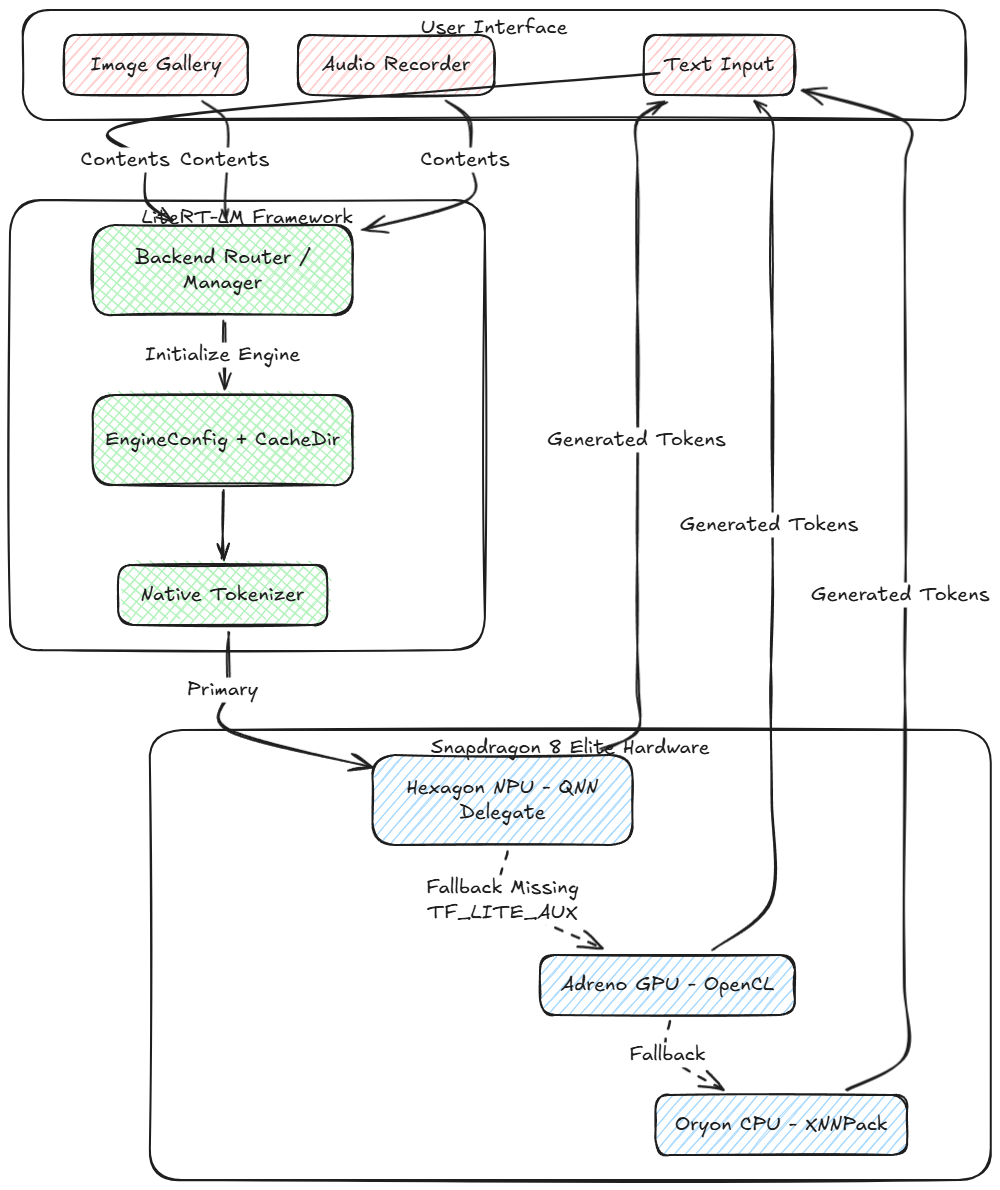
Die Motorarchitektur: LiteRT und LiteRT-LM
Um ein Modell dieser Komplexität auf Android auszuführen, verwenden wir LiterRT (früher TensorFlow Lite) daneben LiteRT-LM (LiteRT für große Modelle). Den Unterschied zwischen den beiden zu verstehen, ist der Schlüssel zur Beherrschung der KI auf Geräten.
LiteRT: Die Ausführungsschicht
Auf der untersten Ebene, LiterRT ist die Laufzeit-Engine, die für die Ausführung des statischen Berechnungsdiagramms des neuronalen Netzwerks verantwortlich ist. Es erfordert die mathematischen Operationen (MatMul, Hinzufügen, Softmax) definiert in der .litertlm (oder .tflite) Datei und ordnet sie der physischen Hardware zu Delegierte.
- XNNPack-Delegierter (CPU): Hochoptimierte Vektormathematik für ARM-Kerne.
- OpenCL/ML-Drift (GPU): Verwendet parallele Rechenfunktionen auf der Adreno-GPU.
- QNN-Delegierter (NPU): Verschiebt quantisierte Ganzzahloperationen für maximale Effizienz auf die Hexagon-NPU.
LiteRT-LM: Die Orchestrierungsebene
Große Sprachmodelle erfordern viel mehr als nur die Ausführung von Diagrammen. Sie erfordern eine aktive, Zustandsbehaftete Schleife. LiteRT-LM fungiert als C++-Orchestrierungsebene (elegant verpackt in einer Kotlin/JNI-API) das sitzt über LiterRT. Es abstrahiert die enorme Komplexität der LLM-Inferenz:
- Native Tokenisierung und Detokenisierung: Anstatt sich auf Python oder langsame Java-Implementierungen zu verlassen, LiteRT-LM bindet direkt an einen hochoptimierten C++-Tokenizer (typischerweise SentencePiece oder BPE) um Text zu kodieren, Audio-, und Vision-Tokens in die Integer-Arrays, die Gemma erwartet.
- KV-Cache-Verwaltung: In LLMs, Um das nächste Wort vorherzusagen, muss man sich an den vorherigen Kontext erinnern. LiteRT-LM ordnet automatisch zu, verwaltet, und aktualisiert den Schlüsselwert (KV) Cache-Tensoren für jedes generierte Token. Gemma 4 geht gekonnt mit dem Neuen um Gemeinsamer KV-Cache Architektur zur Minimierung des Speicherbedarfs.
- Sampler-Konfiguration: Es verwaltet die autoregressive Generierungsschleife und wendet Algorithmen wie Top-K- und Top-P-Sampling nativ in C++ an, bevor es das ausgewählte Token wieder in das LiteRT-Diagramm einspeist.
- Multimodales Content-Routing: Es erfasst Arrays von Content.ImageFile und Content.AudioBytes, leitet sie durch die spezifischen Bild-/Audio-Encoder-Untergraphen, und projiziert sie zusammen mit Text-Tokens in den einheitlichen Einbettungsraum.
Geben Sie Qualcomm QNN ein
Das Samsung S25 Ultra (angetrieben durch den Snapdragon 8 Elite) verfügt über eine leistungsstarke Hexagon-NPU. Durch die Verwendung der Delegierter des Qualcomm Neural Network (QNN).LiteRT kann die massiven Matrixmultiplikationen der Transformatorblöcke von der CPU/GPU direkt auf die NPU verlagern. Dadurch werden der Stromverbrauch und die thermische Drosselung drastisch reduziert und die Anzahl der Token pro Sekunde maximiert (TPS).
Jedoch, die NPU zu nutzen, Das Modell muss bestimmte vorkompilierte QNN-Nutzlastbinärdateien enthalten (TF_LITE_AUX). In Ermangelung dieser, Eine robuste App muss sich ordnungsgemäß auf die GPU verlassen (mit OpenCL/ML Drift) oder die CPU (mit XNNPack).
Systemarchitektur und technische Änderungen
Beim Upgrade unserer Android-Anwendung von Gemma 3 zu Gemma 4, Wir stießen auf mehrere technische Hürden – Von API-Umstellungen bis hin zur Handhabung einer riesigen Nutzlast von 2,58 GB unter modernen Android-Speicherregeln.
Hier ist eine visuelle Darstellung, wie die neue Inferenzpipeline auf dem Gerät funktioniert:
![Bild[1]-Multimodales Gemma bringen 4 E2B bis zum Rand: Ein tiefer Einblick in LiteRT-LM und Qualcomm QNN für Windows 7,8,10,11-Winpcsoft.com](https://winpcsoft.com/wp-content/plugins/wp-fastest-cache-premium/pro/images/blank.gif)
Wichtige Implementierungs-Upgrades
1. LiteRT-LM-Kern-Upgrade
Die Architektur von Gemma 4 (insbesondere PLE und der neue gemeinsame KV-Cache) erfordert die neueste Laufzeit. Wir haben unsere Build-Konfiguration aktualisiert, um die neueste Version der LiteRT-LM-Android-Bibliotheken abzurufen, um die Kompatibilität mit der neuen Modellstruktur sicherzustellen.
2. Multimodale API-Integration
Um die Bild- und Audiofunktionen von Gemma 4 freizuschalten, Wir haben unseren LiteRTLMManager neu gestaltet. Wir sind von reiner Text-sendMessage übergegangen() Aufrufe des neuen multimodalen Content Builders:
val contentParts = mutableListOf<Inhalt>()
contentParts.add(Content.ImageFile(imagePath))
contentParts.add(Content.AudioBytes(audioBytes))
contentParts.add(Inhalt.Text(textPrompt))
val content = Contents.of(*contentParts.toTypedArray())
Zusätzlich, EngineConfig wurde aktualisiert, um Backend-Delegierte speziell für Bild- und Audio-Untermodelle zuzuweisen (z.B. Vorwärtssicht an die GPU, während Audio auf der CPU verbleibt).
3. Überwindung der 2,58-GB-Payload-Grenze (ADB-Push-Workflow)
Das Herunterladen eines 2,58-GB-Modells über eine Standard-HTTP-Verbindung direkt in einer Android-App ist grundsätzlich instabil. Mobilfunknetze sind ausgefallen, HttpURLConnection hat Probleme mit Weiterleitungen und Android 15 Flächengebundene Lagerung schränkt den App-Zugriff auf öffentliche Ordner wie /sdcard/Download/ stark ein.
Die Lösung: Wir haben ein direktes ADB-Push-Erkennungssystem implementiert. Anstatt sich auf In-App-Downloads zu verlassen, Entwickler und Benutzer können das Modell sicher auf ihren PC herunterladen und direkt in das uneingeschränkte externe Datenverzeichnis der App übertragen:
adb push gemma-4-E2B-it.litertlm /sdcard/Android/data/com.example.qnn_litertlm_gemma/files/
Die ModelDownloader-Klasse der App erkennt dies beim Start, validiert die Nutzlastgröße, und initialisiert die Engine sofort ohne Kopieren oder Herunterladen, Dadurch werden die Ladezeiten drastisch reduziert und SocketExceptions eliminiert.
4. Die Fallback-Kette NPU → GPU → CPU
Da Open-Source-Modellgewichte (wie die auf Hugging Face) Oft fehlen die gerätespezifischen vorkompilierten QNN-Binärdateien, Das Erzwingen einer NPU-Verbindung kann zum Absturz der App führen.
Wir haben eine Lazy-Loading-BackendFactory implementiert, die versucht, die NPU hochzufahren. Wenn eine LiteRtLmJniException ausgelöst wird (Es wird ausdrücklich darauf hingewiesen, dass TF_LITE_AUX nicht gefunden wurde), Die App fängt die Ausnahme sofort ab, verlässt die NPU, und initialisiert stattdessen nahtlos das OpenCL-GPU-Backend.
Diplom
Bereitstellung von Gemma 4 E2B auf einem Android-Gerät ist ein Beweis dafür, wie schnell sich Edge AI weiterentwickelt. Durch die Kombination der hochoptimierten Modelle von Google, Die Abstraktion von LiteRT-LM, und Qualcomms Hardwarebeschleunigung, Wir können wahr erreichen, Privat, multimodale Intelligenz direkt in unserer Tasche.
Mit den technischen Engpässen bei den Speicherberechtigungen, Fallback-Routing, und Abhängigkeitsmanagement gelöst, Der Grundstein für die Entwicklung der nächsten Generation datenschutzorientierter Technologien ist gelegt, kontextsensitive mobile Anwendungen.
![]()
Multimodales Gemma bringen 4 E2B bis zum Rand: „A Deep Dive into LiteRT-LM and Qualcomm QNN“ wurde ursprünglich in Google Developer Experts auf Medium veröffentlicht, wo die Leute das Gespräch fortsetzen, indem sie diese Geschichte hervorheben und darauf reagieren.