![imagen[1]-Implementar Gemma 4 en la ejecución en la nube: Pague solo cuando realmente lo use para Windows 7,8,10,11-Winpcsoft.com](https://winpcsoft.com/wp-content/plugins/wp-fastest-cache-premium/pro/images/blank.gif)
Estaba en la sala de París cuando Google anunció Gema 3. Fue un evento emocionante. Las demostraciones fueron impresionantes.. Pero lo que realmente importó sucedió después., de vuelta en mi escritorio, cuando realicé mis propias pruebas y descubrí que las demostraciones no mentían.
Gema 3 Fue el primer modelo abierto que cerró la brecha con los grandes comerciales.. No venció a Géminis. Pero alcanzó el nivel en el que estaba Géminis un año antes.. Para un modelo abierto, podría ejecutarlo en su propia infraestructura., ese fue un salto significativo. Empecé a integrarlo en mis propios pipelines.. Tareas específicas, pequeños pasos, Lugares donde la respuesta no necesita un modelo de frontera para ser correcta..
Entonces cometí un error.
Desplegué a Gemma 3 en Jardín modelo Vertex AI durante un fin de semana para realizar pruebas. lo dejé funcionando. No lo apagué. Volví a un proyecto de ley que me hizo repensar mi relación con la infraestructura de la nube.. Hice un video sobre esto en mi canal de youtube para que otros no repitan el mismo error.
Este artículo es la redención..
Gema 4 recién lanzado. Es un salto más grande que Gemma. 3 era. y esta vez, Lo estoy implementando en Ejecutar en la nube, que escala a cero cuando no lo estás usando. Olvídate de apagarlo. Te reto. No pagarás ni un centavo.
Este artículo está dividido en dos partes.. El primero cubre lo que Gemma 4 es, por qué ejecutar tu propio modelo cambia lo que puedes construir, cómo funciona la pila de implementación, y los datos de rendimiento de mis propias pruebas..
La segunda parte es la guía de implementación paso a paso.. Requisitos previos, Configuración de VPC, subir modelo, implementar comandos para los cuatro tamaños de modelo, y limpieza.
Parte 1: Entendiendo a Gemma 4 en la ejecución en la nube
Lo que cambió en Gemma 4
Gema 4 Se envía en cuatro modelos distintos., ni uno. Dos pequeños y dos grandes, cada uno con una compensación diferente.
| Modelo | Parámetros | Arquitectura | Ventana de contexto |
|---------|----------------------|--------------|----------------|
| E2B | 2.3B efectivo | Denso | 128k fichas |
| E4B | 4.5B efectivo | Denso | 128k fichas |
| 26B A4B | 26B total, 4B activo | Ministerio de Educación | 256k fichas |
| 31B | 31B | Denso | 256k fichas |
El modelo 26B merece una mirada más cercana. se utiliza Mezcla de expertos (Ministerio de Educación) arquitectura: un diseño donde el modelo tiene 26 mil millones de parámetros en el disco pero solo activa 4 mil millones de ellos por token durante la inferencia. Piense en ello como un gran equipo de especialistas al que solo se llama a los expertos relevantes para cada tarea., en lugar de que todos trabajen en cada problema. El resultado: Capacidad que se acerca a un modelo 26B., al costo de cálculo de uno 4B. Esto es muy importante en el momento de la inferencia., como verá en los números a continuación.
Más allá del tamaño, Gema 4 agrega entrada multimodal. Imágenes, audio, video: todos soportados como entradas, con salida de texto. Los modelos pequeños (E2B, E4B) puede procesar video con audio. Los más grandes manejan imágenes con contexto extendido..
Pero las dos mejoras que más importan para cualquiera que construya canales de agentes son razonamiento y llamada de función.
Razonamiento significa que el modelo resuelve un problema paso a paso antes de producir una respuesta., en lugar de saltar directamente a una respuesta. Para tareas complejas que antes requerían un modelo de frontera, una Gemma capaz de razonar 4 ahora puede manejarlos a una fracción del costo. La llamada a funciones también se ha mejorado significativamente., el modelo devuelve de forma fiable llamadas a herramientas estructuradas, que es lo que lo hace componible dentro de un agente que organiza múltiples pasos.
Juntos, Estas dos capacidades cambian el lugar donde Gemma encaja en un sistema de producción.. Mis propios canales dividen el trabajo en capas: pequeño, pasos enfocados que no necesitan un razonamiento profundo, y pasos de orquestación que evalúan los resultados y deciden qué sucede a continuación. Gema 3 podría manejar los pasos simples. Gema 4 También puede manejar más capa intermedia., las tareas que antes necesitaban una mayor, modelo más caro para hacerlo bien. Cada paso que se pasa de una API de frontera a una Gemma autohospedada son tokens por los que dejas de pagar.
Por qué ejecutar su propio modelo cambia lo que puede construir
Primero, Seamos precisos sobre lo que significa "abierto" aquí.. Gema 4 no es de código abierto. El código de entrenamiento, los datos de entrenamiento, y la receta completa que produjo el modelo no es pública. ¿Cuáles son los lanzamientos de Google? pesas, los parámetros entrenados del propio modelo, bajo el apache 2.0 licencia. Puedes descargarlos, ejecutarlos, modificarlos, y construir productos comerciales sobre ellos. Pero no se puede reproducir el proceso de formación..
Esa distinción importa menos de lo que la gente piensa para la mayoría de los casos de uso., y más de lo que la gente piensa para uno específico: sintonia FINA.
porque tienes las pesas, puedes entrenar encima de ellos. Toma el modelo 4B, ejecútelo a través de su propio conjunto de datos específico de dominio, y producir una versión que comprenda su terminología, sigue su formato de salida, y funciona mejor en sus tareas específicas que el modelo de propósito general. Este es el camino desde un “modelo abierto capaz” hasta un “modelo que conoce su negocio”. Los datos que utiliza para realizar ajustes nunca abandonan su entorno, y el resultado te pertenece.
Existe una categoría de problema que los grandes modelos alojados en la nube no pueden resolver para ciertos clientes. No porque los modelos no sean capaces, pero porque los datos no pueden salir del edificio.
Proveedores de atención médica, instituciones financieras, firmas legales. Las organizaciones con serias obligaciones de privacidad de datos no pueden canalizar información confidencial a través de API externas.. Para ellos, Una IA poderosa siempre ha significado exponer datos a la infraestructura de otra persona.. Esto es imposible en muchos entornos regulados..
Una Gemma autohospedada en su propio servicio Cloud Run cambia la ecuación. El modelo se ejecuta en su proyecto., su VPC, tu infraestructura. Los datos nunca salen.
Pero el ejemplo más convincente no está en una oficina.. esta en un campo.
Imagina un dron con cámaras volando sobre tierras de cultivo., Uso de visión y razonamiento por computadora para detectar enfermedades de cultivos., identificar problemas de riego, o detectar daños por plagas. Ese dron no puede esperar a una llamada API de ida y vuelta a un punto final en la nube. Es posible que ni siquiera tenga una conexión a Internet confiable en una ubicación rural remota.. La decisión debe ocurrir en el dispositivo., o cerca de él. Y tiene que suceder rápido.
La capacidad multimodal de Gemma 4, combinado con sus tamaños de modelo pequeños, hace que ese tipo de implementación en el dispositivo o en el borde sea práctica. Un modelo 2B o 4B puede funcionar con hardware que un dron o un sensor industrial podría transportar o conectar de manera realista.. La capacidad de razonamiento significa que puede hacer más que clasificar.. Puede pensar en lo que está viendo..
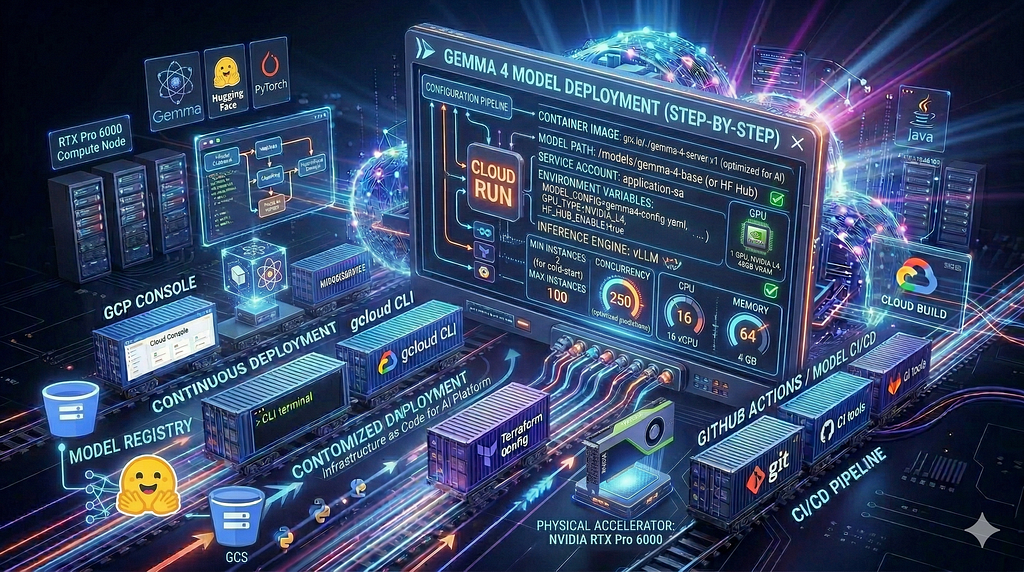
Cómo Gemma 4 Se implementa: La pila
cuando gema 3 salió, la implementación típica utilizada Ser, una herramienta diseñada para ejecutar modelos localmente. es simple, funciona bien para modelos pequeños, y puedes hacer que algo funcione rápidamente. Ollama hornea los pesos del modelo directamente en la imagen del contenedor.. El contenedor comienza, el modelo ya esta ahi, y estás sirviendo en segundos. Para un modelo 2B o 7B esto está bien..
Los modelos más grandes de Gemma 4 rompen ese patrón. Un modelo 31B no cabe cómodamente en una imagen de contenedor. No puedes convertir 65 GB de peso en algo que esperas implementar y escalar rápidamente. Ollama tampoco expone los controles de producción que necesita a escala: solicitar lotes, Uso compartido de caché KV entre solicitudes simultáneas, Cuantización que no sacrifica la precisión.. Es una gran herramienta local.. No está diseñado para lo que estamos construyendo aquí..
Usos de la ruta oficial de Gemma 4 vllm en cambio. vLLM es un motor de inferencia creado específicamente para brindar servicios a los LLM en producción.. Maneja múltiples solicitudes simultáneas de manera eficiente al agruparlas en lotes., comparte el caché KV entre solicitudes para reducir la presión de la memoria, y soporta cuantización fp8, que es lo que permite que el modelo 31B encaje dentro del NVIDIA RTX Pro 6000 Blackwell96 GB de VRAM sin pérdida de calidad significativa. No hay clúster que administrar, no hay grupo de nodos para configurar. Una bandera en su comando de implementación.
Para los modelos 26B y 31B, hay una tercera pieza: el Correr:Streamer modelo AI. En lugar de esperar a que se cargue todo el modelo antes de atender la primera solicitud, la serpentina recoge pesas en paralelo desde Almacenamiento en la nube de Google mientras vLLM se inicializa. El modelo comienza a aceptar solicitudes antes de que esté completamente cargado.. Esto es lo que hace que los arranques en frío de modelos grandes en Cloud Run sean factibles en lugar de dolorosos..
La decisión de carga del modelo: HuggingFace y GCS
Antes de implementar, hay una elección que afecta a todo lo demás: ¿De dónde viene el modelo al inicio??
AbrazosCara es la opción sencilla. El contenedor descarga los pesos del modelo en cada arranque en frío.. Sin coste de almacenamiento, sin configuración inicial. La compensación: estás descargando a través de Internet público cada vez, y ese tiempo de descarga domina tu arranque en frío.
Almacenamiento en la nube de Google es la opción de producción. Subes los pesos una vez., y el contenedor los transmite desde GCS en cada arranque en frío a través de Run:Streamer modelo AI. Más configuración por adelantado. Pero la transmisión se realiza a través de la red interna de Google., y la diferencia de velocidad es significativa.
Aquí está la parte que me sorprendió cuando la probé.: GCS sin la configuración adecuada de VPC en realidad es Más lento que HuggingFace para modelos pequeños. La carrera:La ventaja de AI Streamer solo se materializa cuando el tráfico permanece en la red interna de Google.. Cuando sale a la internet pública, los gastos generales eliminan el beneficio.
La solución es Acceso privado a Google en su subred VPC. un comando. Abre una ruta desde su contenedor Cloud Run a las API de Google (incluyendo GCS) sin tocar la internet pública. La documentación oficial no destaca esto., y es el detalle más importante de toda esta guía..
Los números
Implementé los cuatro tamaños de modelo de HuggingFace y de GCS, con y sin VPC, y tiempo de arranque en frío medido (primera solicitud después de escalar a cero), tiempo hasta la primera ficha, y cálido tiempo de respuesta. El mismo mensaje cada vez: “¿Qué es la luna??"
Una nota sobre la metodología: estas son medidas unicas, no son promedios de un conjunto completo de pruebas comparativas. Los LLM son no deterministas por naturaleza, y el rendimiento de la infraestructura varía con la carga, capacidad de la región, y condiciones de la red. Los números a continuación son direccionalmente correctos., no es científicamente preciso. Utilícelos para comprender las compensaciones relativas entre las opciones de implementación.. Antes de comprometerse con un enfoque en la producción, ejecute sus propias pruebas con su propia carga de trabajo.
| Modelo | Fuente | Arranque en frío | Respuesta cálida |
|-------|--------------|------------|---------------|
| 2B | AbrazosCara | 311s | 1.75s |
| 2B | GCS (sin VPC) | 334s | 1.81s |
| 2B | GCS + VPC | **245s** | 1.81s |
| 4B | AbrazosCara | 452s | 2.46s |
| 4B | GCS (sin VPC) | 433s | 2.47s |
| 4B | GCS + VPC | **246s** | 2.47s |
| 26B | GCS + VPC | **191s** | 1.61s |
| 31B | GCS + VPC | **251s** | 5.90s |
Algunas cosas para desempacar.
GCS sin VPC es más lento que HuggingFace para modelos pequeños. El transmisor agrega una sobrecarga que solo vale la pena cuando el tráfico es rápido.. A través de Internet público, HuggingFace gana para archivos pequeños.
VPC lo cambia todo. Con acceso privado a Google, el arranque en frío 4B cae de 433 segundos para 246 artículos de segunda clase. Eso es un 43% reducción simplemente por enrutar el tráfico de manera diferente.
El modelo 26B arranca en frío más rápido que el 2B de HuggingFace. Lee eso de nuevo. A 26 modelo de mil millones de parámetros, transmitido a través de la red interna de Google, está listo para servir en 191 artículos de segunda clase. La descarga de 2B desde HuggingFace tarda 311 artículos de segunda clase. La ruta de red y la arquitectura de transmisión importan más que el tamaño del modelo en el disco.
Ministerio de Educación vs.. Materias densas en el momento de la inferencia., no solo inicio. La cálida respuesta del 26B es 1.61 artículos de segunda clase. El 31B es 5.90 artículos de segunda clase. El 31B es un modelo denso.: cada uno de sus 31 mil millones de parámetros participan en cada token. El 26B sólo se activa 4 mil millones a la vez. Es por eso que el 26B responde casi cuatro veces más rápido a pesar de ser nominalmente "más grande". Para aplicaciones sensibles a la latencia con un requisito de contexto de 256k, el 26B A4B es la opción más interesante.
Escalar a cero y lo que significa para el costo
Cloud Run escala las instancias en ejecución según el tráfico. Cuando no hay solicitudes, escala a cero. Sin instancias, no hay GPU asignada, sin costo. En el momento en que llega una solicitud, comienza una nueva instancia, carga el modelo, y lo sirve.
Esto es fundamentalmente diferente de Vertex AI Model Garden., donde un punto final implementado mantiene viva una instancia en ejecución. Aléjate durante el fin de semana, volver a una factura.
Con la escala a cero de Cloud Run, el peor caso es el retraso del arranque en frío. Y como muestran los números, Incluso un modelo 26B está listo en unos tres minutos.. Para desarrollo y pruebas, esa compensación es sencilla.
Para verificar que una instancia se haya escalado a cero: abre la consola de Cloud Run, haga clic en su servicio, ve al Métrica pestaña, y mira recuento de instancias. Cero significa que no se le cobrará. O simplemente espera 5 minutos después de su última solicitud y enviar una nueva. si es necesario 200+ segundos en lugar de 2, la instancia reducida.
La escala a cero es la elección correcta para el desarrollo y las pruebas. Pero no es la única opción. Cloud Run también te permite establecer un número mínimo de instancias para mantenerse vivo en todo momento. Para una producción que atienda un tráfico constante, configuraría al menos una instancia cálida para eliminar por completo los arranques en frío. Eso cambia el modelo de costos, estás pagando por el tiempo de inactividad otra vez, pero es una compensación deliberada, no es un accidente.
La guía de este artículo está optimizada para realizar pruebas.: costo mínimo, máxima flexibilidad, escala a cero en todo. Cuando esté listo para pasar a producción y necesite pensar en instancias mínimas, ajuste de concurrencia, y gestión del tráfico, mi publicación “Esto es Cloud Run: Configuración" cubre esas opciones.
Parte 2: La guía de implementación
Ejecuté todo esto yo mismo antes de escribir una palabra de esta guía.. Implementado todos los tamaños de modelo., golpear cada error, depurado cada fallo. Las instrucciones a continuación son las que realmente funcionan para mí..
Lo que necesitarás
- Un proyecto de Google Cloud con facturación habilitada
- Concha de nube (recomendado) o el CLI de gcloud instalado localmente. This guide assumes you're using Cloud Shell.
- Acceso a la Gema 4 modelos en AbrazosCara (Requiere aceptar la licencia para cada modelo.)
- A Token de acceso a HuggingFace con acceso de lectura
Ejecuté todo lo siguiente desde Concha de nube. Terminal basado en navegador de Google Cloud, autenticado previamente con su cuenta y gcloud ya instalado. Sin configuración local, no hay discrepancias de versión. Ábralo desde Cloud Console haciendo clic en el ícono de terminal en la parte superior derecha.
Paso 1: Establezca sus variables de entorno
Configúrelos una vez al inicio de su sesión de Cloud Shell. Cada comando en esta guía los usa:
export GOOGLE_CLOUD_PROJECT="your-project-id"
export GOOGLE_CLOUD_REGION="us-central1"
export GCS_BUCKET="${GOOGLE_CLOUD_PROJECT}-caché de modelo"
export VPC_NETWORK="gemma-vpc"
export VPC_SUBNET="gemma-subnet"
export HF_TOKEN="your-huggingface-token"
exportar PROJECT_NUMBER=$(gcloud projects describe "${GOOGLE_CLOUD_PROJECT}" \
--format='value(número de proyecto)')
Nota 1: RTX Pro 6000 disponible en us-central1 y europe-west4
Nota 2: Las sesiones de Cloud Shell no conservan las variables de entorno entre las reconexiones. Si cierra y vuelve a abrir Cloud Shell, ejecute este bloque nuevamente antes de continuar.
Paso 2: Habilite las API requeridas
En un nuevo proyecto, necesitarás todos estos:
habilitar los servicios de gcloud \
run.googleapis.com \
Compute.googleapis.com \
almacenamiento.googleapis.com \
artefactoregistry.googleapis.com \
iam.googleapis.com \
--proyecto $GOOGLE_CLOUD_PROJECT
Compute.googleapis.com es necesario para los recursos de VPC y GPU.. Se necesita iam.googleapis.com para otorgar permisos al agente del servicio Cloud Run.. Los demás cubren el almacenamiento de modelos y el propio Cloud Run..
Paso 3: Verificar cuota de GPU (opcional)
El acceso a Cloud Run GPU requiere aprobación de cuota. Puedes consultar tu asignación actual:
Ir a SOY & Administración > Cuotas & Límites del sistema en el Consola de Google Cloud, filtrar por NVIDIA_RTX_PRO_6000 y región:us-central1. Si el límite es 0 or the quota doesn't appear, necesitas solicitarlo.
Solicitar cuota de GPU a través del Página de cuotas de Cloud Run. La aprobación no es instantánea., permitir unos días.
Paso 4: Crear la VPC
Como se explica en la parte 1, El acceso privado a Google en la subred es el paso crítico. sin eso, el contenedor no puede llegar a GCS en absoluto. Se incluye directamente en el comando de creación de subredes a continuación — no se necesita una actualización por separado.
gcloud compute networks create "${VPC_NETWORK}" \
--modo-subred=personalizado \
--modo-enrutamiento-bgp=regional \
--project="${GOOGLE_CLOUD_PROJECT}"
gcloud compute networks subnets create "${VPC_SUBNET}" \
--network="${VPC_NETWORK}" \
--region="${GOOGLE_CLOUD_REGION}" \
--rango=10.0.0.0/24 \
--habilitar-ip-privada-acceso-google \
--project="${GOOGLE_CLOUD_PROJECT}"
Otorgar permiso al agente del servicio Cloud Run para usar la subred:
gcloud projects add-iam-policy-binding "${GOOGLE_CLOUD_PROJECT}" \
--member="serviceAccount:servicio-${PROYECTO_NÚMERO}@serverless-robot-prod.iam.gserviceaccount.com" \
--role="roles/compute.networkUser"
Nota: En producción, en lugar de utilizar la cuenta de servicio informático predeterminada, cree uno dedicado con acceso con privilegios mínimos al depósito de GCS.
Paso 5: Cree el depósito de GCS y cargue modelos
Cree un depósito de una sola región en la misma región que su servicio Cloud Run:
gcloud storage buckets create "gs://${GCS_BUCKET}" \
--location="${GOOGLE_CLOUD_REGION}" \
--acceso uniforme a nivel de cubo \
--project="${GOOGLE_CLOUD_PROJECT}"
gcloud storage buckets add-iam-policy-binding "gs://${GCS_BUCKET}" \
--member="serviceAccount:${PROYECTO_NÚMERO}[email protected]" \
--role="roles/storage.objectViewer"
En espacio en disco: El 2B (~5GB) y 4B (~9GB) Los modelos caben en Cloud Shell.. El 26B (~50GB) y 31B (~65GB) no. Cloud Shell tiene aproximadamente 5 GB de disco. Para los modelos grandes, activar una máquina virtual GCE temporal:
Las instancias informáticas de gcloud crean gemma-uploader \
--project="${GOOGLE_CLOUD_PROJECT}" \
--zone="${GOOGLE_CLOUD_REGION}-a" \
--tipo-máquina=n2-estándar-8 \
--tamaño del disco de arranque = 300 GB \
--tipo-de-disco-de-arranque=pd-ssd \
--familia-imagen=debian-12 \
--proyecto-imagen=nube-debian \
--red = predeterminado \
--subred=predeterminado \
--ámbitos = almacenamiento lleno
Si recibe un error de subred, intenta configurar –network="${VPC_NETWORK}" –subnet="${VPC_SUBNET}"
Gcloud Compute SSH Gemma-Uploader \
--project="${GOOGLE_CLOUD_PROJECT}" \
--zone="${GOOGLE_CLOUD_REGION}-a" \
--network="${VPC_NETWORK}" \
--subnet="${VPC_SUBNET}"
Dentro de la máquina virtual, instalar dependencias y subir los modelos:
export HF_TOKEN="your-huggingface-token"
export GCS_BUCKET="your-bucket-name"
sudo apt-obtener actualización && sudo apt-get install -y python3-pip --fix-missing
python3 -m pip instalar huggingface_hub hf_transfer --break-system-packages
# Deténgase inmediatamente si falla algún paso
conjunto -e
# Descargar, subir, y limpiar cada modelo uno a la vez
for MODEL in "google/gemma-4-E2B-it:gemma-4-E2B-it" \
"google/gemma-4-E4B-it:gemma-4-E4B-it" \
"google/gemma-4-26B-A4B-it:gemma-4-26B-A4B-it" \
"google/gemma-4-31B-it:gemma-4-31B-it"; hacer
REPO="${MODELO%%:*}"
DIR="${MODELO##*:}"
export HF_HOME="/tmp/hf_cache_${dirección}"
python3-c "
desde huggingface_hub importar snapshot_download
importar sistema operativo
instantánea_descargar(repo_id='${REPO}', local_dir='/tmp/${dirección}', token=os.entorno['HF_TOKEN'])
"
cp de almacenamiento de gcloud /tmp/${dirección}/* "gs://${GCS_BUCKET}/modelos/${dirección}/" --recursivo
rm -rf/tmp/${dirección} "/tmp/hf_cache_${dirección}"
hecho
Salga de la VM y elimínela:
salida
Las instancias informáticas de gcloud eliminan gemma-uploader \
--project="${GOOGLE_CLOUD_PROJECT}" \
--zone="${GOOGLE_CLOUD_REGION}-a" \
--tranquilo
Paso 6: Desplegar
Cada implementación utiliza la misma imagen de contenedor prediseñadas de Google:
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:gemma4
Un detalle importante cubierto en la Parte 1: el contenedor no lee el modelo o los indicadores vLLM de las variables de entorno. Deben pasar por –command="vllm" y –argumentos. Sin –command="vllm", el script de inicio falla inmediatamente.
2modelo B:
export GCS_MODEL_PATH_2B="gs://${GCS_BUCKET}/modelos/gemma-4-E2B-it"
Implementación de ejecución beta de gcloud gemma4-2b \
--image="us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:gemma4" \
--project="${GOOGLE_CLOUD_PROJECT}" \
--region="${GOOGLE_CLOUD_REGION}" \
--entorno de ejecución = gen2 \
--permitir no autenticado \
--procesador = 20 \
--memoria=80Gi \
--GPU=1 \
--tipo-gpu=nvidia-rtx-pro-6000 \
--sin-redundancia-zonal-gpu \
--sin aceleración de la CPU \
--instancias máximas = 1 \
--simultaneidad=64 \
--tiempo de espera = 600 \
--network="${VPC_NETWORK}" \
--subnet="${VPC_SUBNET}" \
--vpc-egress=todo el tráfico \
--command="vllm" \
--args="serve,${GCS_MODEL_PATH_2B},--habilitar-precarga-fragmentada,--habilitar-caching-prefijo,--generación-config=auto,--habilitar-elección-de-herramienta-automática,--tool-call-parser=gemma4,--reasoning-parser=gemma4,--dtype=bfloat16,--max-num-seqs=64,--gpu-memory-utilization=0.95,--load-format=runai_streamer,--tamaño-paralelo-tensor=1,--puerto=8080,--host=0.0.0.0" \
--startup-probe="tcpSocket.port=8080,initialDelaySeconds=60,failureThreshold=5,timeoutSeconds=60,periodSeconds=60"
4modelo B: mismo comando, reemplace GCS_MODEL_PATH_2B con GCS_MODEL_PATH_4B, nombre del servicio con gemma4-4b.
export GCS_MODEL_PATH_4B="gs://${GCS_BUCKET}/modelos/gemma-4-E4B-it"
Implementación de ejecución beta de gcloud gemma4-4b \
--image="us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:gemma4" \
--project="${GOOGLE_CLOUD_PROJECT}" \
--region="${GOOGLE_CLOUD_REGION}" \
--entorno de ejecución = gen2 \
--permitir no autenticado \
--procesador = 20 \
--memoria=80Gi \
--GPU=1 \
--tipo-gpu=nvidia-rtx-pro-6000 \
--sin-redundancia-zonal-gpu \
--sin aceleración de la CPU \
--instancias máximas = 1 \
--simultaneidad=64 \
--tiempo de espera = 600 \
--network="${VPC_NETWORK}" \
--subnet="${VPC_SUBNET}" \
--vpc-egress=todo el tráfico \
--command="vllm" \
--args="serve,${GCS_MODEL_PATH_4B},--habilitar-precarga-fragmentada,--habilitar-caching-prefijo,--generación-config=auto,--habilitar-elección-de-herramienta-automática,--tool-call-parser=gemma4,--reasoning-parser=gemma4,--dtype=bfloat16,--max-num-seqs=64,--gpu-memory-utilization=0.95,--load-format=runai_streamer,--tamaño-paralelo-tensor=1,--puerto=8080,--host=0.0.0.0" \
--startup-probe="tcpSocket.port=8080,initialDelaySeconds=60,failureThreshold=5,timeoutSeconds=60,periodSeconds=60"
26modelo B: agrega cuantización fp8 y elimina la concurrencia a 8.
La sonda de inicio a continuación permite 6 minutos totales (1 minuto de retraso inicial + 5 cheques × 1 minuto cada uno), basado en mi tiempo de carga medido. Si su implementación se agota, aumentar el umbral de falla — cada unidad agrega un minuto más:
export GCS_MODEL_PATH_26B="gs://${GCS_BUCKET}/modelos/gemma-4-26B-A4B-it"
Implementación de ejecución beta de gcloud gemma4-26b \
--image="us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:gemma4" \
--project="${GOOGLE_CLOUD_PROJECT}" \
--region="${GOOGLE_CLOUD_REGION}" \
--entorno de ejecución = gen2 \
--permitir no autenticado \
--procesador = 20 \
--memoria=80Gi \
--GPU=1 \
--tipo-gpu=nvidia-rtx-pro-6000 \
--sin-redundancia-zonal-gpu \
--sin aceleración de la CPU \
--instancias máximas = 1 \
--simultaneidad=8 \
--tiempo de espera = 600 \
--network="${VPC_NETWORK}" \
--subnet="${VPC_SUBNET}" \
--vpc-egress=todo el tráfico \
--command="vllm" \
--args="serve,${GCS_MODEL_PATH_26B},--habilitar-precarga-fragmentada,--habilitar-caching-prefijo,--generación-config=auto,--habilitar-elección-de-herramienta-automática,--tool-call-parser=gemma4,--reasoning-parser=gemma4,--dtype=bfloat16,--quantization=fp8,--kv-cache-dtype=fp8,--max-num-seqs=8,--gpu-memory-utilization=0.95,--load-format=runai_streamer,--tamaño-paralelo-tensor=1,--puerto=8080,--host=0.0.0.0,--max-model-len=32767" \
--startup-probe="tcpSocket.port=8080,initialDelaySeconds=60,failureThreshold=5,timeoutSeconds=60,periodSeconds=60"
31modelo B: Igual que 26B con FailureThreshold=6, permitiendo 7 minutos totales según mi tiempo de carga medido. Aumente el umbral de falla si es necesario, se aplica la misma regla: cada unidad suma un minuto:
export GCS_MODEL_PATH_31B="gs://${GCS_BUCKET}/modelos/gemma-4-31B-it"
Implementación de ejecución beta de gcloud gemma4-31b \
--image="us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:gemma4" \
--project="${GOOGLE_CLOUD_PROJECT}" \
--region="${GOOGLE_CLOUD_REGION}" \
--entorno de ejecución = gen2 \
--permitir no autenticado \
--procesador = 20 \
--memoria=80Gi \
--GPU=1 \
--tipo-gpu=nvidia-rtx-pro-6000 \
--sin-redundancia-zonal-gpu \
--sin aceleración de la CPU \
--instancias máximas = 1 \
--simultaneidad=8 \
--tiempo de espera = 600 \
--network="${VPC_NETWORK}" \
--subnet="${VPC_SUBNET}" \
--vpc-egress=todo el tráfico \
--command="vllm" \
--args="serve,${GCS_MODEL_PATH_31B},--habilitar-precarga-fragmentada,--habilitar-caching-prefijo,--generación-config=auto,--habilitar-elección-de-herramienta-automática,--tool-call-parser=gemma4,--reasoning-parser=gemma4,--dtype=bfloat16,--quantization=fp8,--kv-cache-dtype=fp8,--max-num-seqs=8,--gpu-memory-utilization=0.95,--load-format=runai_streamer,--tamaño-paralelo-tensor=1,--puerto=8080,--host=0.0.0.0,--max-model-len=32767" \
--startup-probe="tcpSocket.port=8080,initialDelaySeconds=60,failureThreshold=6,timeoutSeconds=60,periodSeconds=60"
Obtenga las URL del servicio después de la implementación:
exportar SERVICE_URL_2B=$(Los servicios de ejecución de gcloud describen gemma4-2b \
--region="${GOOGLE_CLOUD_REGION}" \
--project="${GOOGLE_CLOUD_PROJECT}" \
--format="value(estado.url)")
exportar SERVICE_URL_4B=$(Los servicios de ejecución de gcloud describen gemma4-4b \
--region="${GOOGLE_CLOUD_REGION}" \
--project="${GOOGLE_CLOUD_PROJECT}" \
--format="value(estado.url)")
exportar SERVICE_URL_26B=$(Los servicios de ejecución de gcloud describen gemma4-26b \
--region="${GOOGLE_CLOUD_REGION}" \
--project="${GOOGLE_CLOUD_PROJECT}" \
--format="value(estado.url)")
exportar SERVICE_URL_31B=$(Los servicios de ejecución de gcloud describen gemma4-31b \
--region="${GOOGLE_CLOUD_REGION}" \
--project="${GOOGLE_CLOUD_PROJECT}" \
--format="value(estado.url)")
echo "2B: $SERVICIO_URL_2B"
echo "4B: $SERVICIO_URL_4B"
echo "26B: $SERVICIO_URL_26B"
echo "31B: $SERVICIO_URL_31B"
Paso 7: Pruébalo
El servicio expone una API compatible con OpenAI. Cualquier cliente que hable el protocolo OpenAI trabaja en su contra..
La primera solicitud será lenta.. Si la instancia se ha escalado a cero, Cloud Run necesita iniciar uno nuevo y cargar el modelo antes de responder. Para los modelos 2B y 4B, espere alrededor 4 minutos. Para el 26B y 31B, arriba a 5 minutos. No canceles la solicitud — volverá. Cada solicitud posterior será rápida..
curl -X POST "${SERVICIO_URL_2B}/v1/chat/finalizaciones" \
-H "Content-Type: aplicación/json" \
-d '{
"model": "google/gemma-4-E2B-it",
"messages": [{"role": "user", "content": "What is the moon?"}],
"max_tokens": 200
}'
El nombre del modelo en la solicitud debe coincidir con el ID del repositorio de HuggingFace pasado. –argumentos (o una costumbre –nombre-modelo-servido si configura uno).
Endurecimiento de producción
Todo lo anterior utiliza –permitir la cuenta no autenticada y la cuenta de servicio informático predeterminada. That's fine for testing. Ante usuarios reales o datos reales:
Autenticación. Reemplazar –permitir no autenticado con –no-permitir-no autenticado. Soporte para ejecución en la nube fichas OIDC para llamadas de servicio a servicio y PAI para acceso de cara al usuario.
Cuenta de servicio dedicada. Cree uno con solo roles/storage.objectViewer en el depósito del modelo. La cuenta de servicio informático predeterminada tiene permisos más amplios de los necesarios.
Punto final privado. Para cargas de trabajo sensibles, elimine la URL pública y acceda al servicio solo desde su VPC a través de Configuración de ingreso a Cloud Run.
Limpiar
Para eliminar todo después de realizar la prueba, ejecute estos comandos en orden:
Eliminar los servicios de Cloud Run:
para SERVICIO en gemma4-2b gemma4-4b gemma4-26b gemma4-31b; hacer
servicios de ejecución de gcloud eliminar $SERVICE \
--region="${GOOGLE_CLOUD_REGION}" \
--project="${GOOGLE_CLOUD_PROJECT}" \
--tranquilo
hecho
Eliminar el depósito de GCS y todos los pesos del modelo:
gcloud storage rm -r "gs://${GCS_BUCKET}" Eliminar la subred y la red de VPC:
gcloud compute networks subnets delete "${VPC_SUBNET}" \
--region="${GOOGLE_CLOUD_REGION}" \
--project="${GOOGLE_CLOUD_PROJECT}" \
--tranquilo
gcloud compute networks delete "${VPC_NETWORK}" \
--project="${GOOGLE_CLOUD_PROJECT}" \
--tranquilo
Si la eliminación de la subred falla y aparece un error sobre las direcciones IP que aún están en uso: Cloud Run conserva las direcciones IP internas durante un período después de que se eliminan los servicios. Nada que los libere por la fuerza. Espera unas horas y vuelve a intentarlo..
Quitar el enlace IAM:
gcloud projects remove-iam-policy-binding "${GOOGLE_CLOUD_PROJECT}" \
--member="serviceAccount:servicio-${PROYECTO_NÚMERO}@serverless-robot-prod.iam.gserviceaccount.com" \
--role="roles/compute.networkUser"
El panorama más amplio
Comencé este artículo hablando de una visita a París y una factura inesperada de la nube.. Pero la verdadera razón por la que dediqué tiempo a buscar a Gemma 4 Ejecutar en Cloud Run no es solo el costo.
es el acceso.
Cuando un LLM se ejecuta en su propia infraestructura, Se hacen posibles cosas que antes no eran posibles.. Los datos regulados que no podían acceder a una API de terceros ahora pueden ser procesados por un modelo capaz. La privacidad se convierte en una característica de la arquitectura., no es un compromiso contra la capacidad.
Pero también hay un argumento más práctico.. Los modelos de frontera comercial son caros por token, y vienen con límites de tarifas regionales que limitan cuánto puedes hacer. Cuando su canal de producción alcanza un límite de velocidad, lo ralentizará. Cuando golpeas tu propio modelo, no hay límite de tarifa. Tu controlas la capacidad. Tu controlas el costo. Tú decides cuándo escalar.
Gema 4 es el primer modelo abierto en el que esa compensación realmente tiene sentido en toda la gama de tareas de IA: texto, visión, razonamiento, llamada de función. No todos los pasos de su proceso necesitan un modelo de frontera. Los pasos que no, y con la capacidad de razonamiento de Gemma 4, Son más pasos que antes., puede ejecutarse en la infraestructura de su propiedad, a un costo que tu controlas, sin límite de tarifa a la vista.
El dron sobrevolando los campos de los agricultores, tomando decisiones por si solo, no es hipotético. Lo único que faltaba era un modelo lo suficientemente bueno como para funcionar con hardware que cabe en una mochila..
Ahora hay uno. Y sabes cómo implementarlo.. Disfruta descubriéndolo.
![]()
Implementar Gemma 4 en la ejecución en la nube: Pague solo cuando realmente lo use se publicó originalmente en Google Developer Experts en Medium, donde las personas continúan la conversación resaltando y respondiendo a esta historia.