By Geeta Kakrani | Google AI developer expert
![imagen[1]-TPU Just Got Split in Two — and It Changes Everything About AI Infrastructure For Windows 7,8,10,11-Winpcsoft.com](https://winpcsoft.com/wp-content/plugins/wp-fastest-cache-premium/pro/images/blank.gif)
Imagine you run a restaurant. For years they had a chef who took care of sourcing the ingredients, preparing, cooking, serving and cleaning. A person. All jobs. It worked when you had 20 customers a day.
Now you have 2 million customers. Every single day. And everyone wants their food in less than two seconds.
You don’t hire a single super chef. You shared the kitchen.
That’s exactly what Google just did with its TPUs.
A decade in which one chip does everything
Desde 2016, Google’s Tensor Processing Units have been the silent engine behind every Google product you use – Buscar, Translate, Photos and Gemini. A family of chips designed for both Train AI models and run them.
For years that was fine.
But then AI agents came. Systems that don’t just answer one question – they think, plan, remember and take action in multiple steps. Millions of them run simultaneously and in real time.
Suddenly a chip that was doing everything was no longer working.
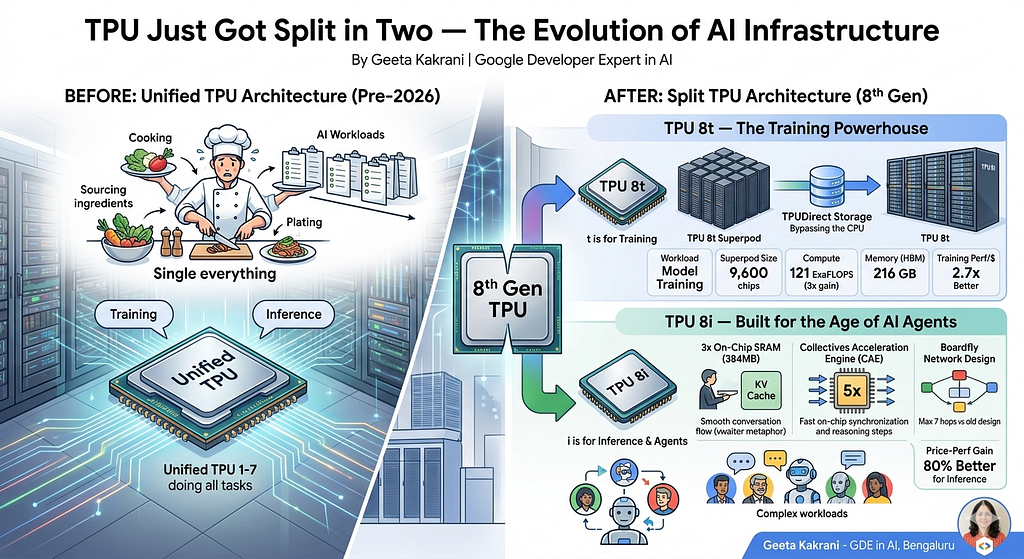
At Google Cloud Next 2026, Google made an announcement that has been ten years in the making: The 8th generation TPU is actually two completely different chips.
Meet TPU 8t Y TPU 8i.
The problem that each of them solves
Here’s a simple way to think about it.
Training an AI model is like writing a novel. You lock yourself in a room for months. You need enormous concentration, enormous resources and are in no hurry to show the draft to anyone. When it’s done, it’s done.
Running an AI model is like performing this novel as a live play – every night in front of a million simultaneous viewers. You must be quick and fluent and definitely not pause in the middle of a sentence waiting for a prop to arrive.
Same story. Completely different skills required.
Google has finally stopped requiring a chip to do both.
TPU 8t – The training powerhouse
The “t” stands for training. And the numbers here are staggering.
A TPU 8t Superpod holds 9,600 chips work together as a single system – with 2 petabytes of shared storage. That’s roughly the storage equivalent of 400 million books, all accessible at the same time.
The calculation? 121 ExaFLOPS. Almost three times as much as the previous generation.
If the previous chip could fill an Olympic-sized swimming pool in an hour, TPU 8t fills three.
Google has also solved a long-standing bottleneck: data transfer. Until now, chips had to route data via the CPU – just like every order in a restaurant goes through an overwhelmed manager. TPU 8t completely bypasses this TPUDirect memorywhich allows chips to communicate directly with data. Transfer speeds have effectively been doubled.
El resultado: 2.7x better exercise performance per dollar about the last generation.
TPU 8i – Built for the age of AI agents
This is where things get really interesting.
The “i” is used for inference – but honestly, it should stand for Intelligence at scale. Because TPU 8i was not only developed for running AI models. It was specifically designed for the chaotic, complex real-time world of AI agents.
Google made three radical changes:
1. Triple the on-chip memory
When an AI is in the middle of a conversation with you, it stores a continuous record of everything said – a so-called KV cache. On older chips, this data set kept overflowing into slower memory, forcing the chip to stop and retrieve data. Like a waiter who keeps forgetting orders and running back to the kitchen.
TPU 8i has 3x more on-chip SRAM (384 MEGABYTE). The entire conversation remains on the chip. No break. No fetching. Just flow.
2. A brand new engine for quick thinking
AI agents that think—the kind that think step by step before responding—must constantly keep all of their cores in sync with each other. In old chips, this synchronization was a bottleneck.
Google has replaced the old system with something called Collective Acceleration Engine (CAE). The entire synchronization is almost latency-free. El resultado: 5x faster on-chip communication. For an agent managing a complex chain of thought, this is the difference between feeling instantaneous and feeling inert.
3. A completely new way for chips to communicate with each other
Imagine a city where every street leads through the town square. This was the old network design – a 3D grid in which messages could fit between chips 16 hops arrive.
Google has labeled the entire road system with something called “ Boardfly. It’s a hierarchical network – small groups of chips that are fully interconnected and then connected to larger groups via optical switches. How long does a message have to travel? 7 hops. A reduction of 56%.
For AI agents using modern architectures like Mixture-of-Experts – where different parts of the model must constantly work together – this is a transformation.
The combined result of all three changes: 80% better value for money for inference compared to the previous generation.
Through the numbers
TPU 8tTPU 8iCreated for trainingInference and agentsChips per system9,6001,152On-chip SRAM128 MB384 MBStorage (HBM)216 GB288 GBNetwork design3D TorusBoardfly (max. 7 hops)Key innovationTPUDirect StorageCAE (5x latency reduction)Performance increase2.7x over Ironwood80% better Value for money
And then Google did something it had never done before
For ten years, TPUs were Google’s private weapon. You could use them on Google Cloud – but you couldn’t own one.
That has just changed.
Google has announced that it will start Direct sales of TPUs to select customers – AI labs, financial institutions and high-performance computing organizations – to operate in their own data centers.
The secret weapon is now a product.
Why this moment is important
The division of TPU into 8t and 8i is not just a hardware story. It’s Google saying out loud what engineers have known silently for years:
Training AI and running AI are two fundamentally different problems. It’s time to stop pretending that one chip can solve both.
As the world moves deeper into the agent age – where AI systems not only react but also think, plan and act – the underlying infrastructure must also evolve. Purpose-built is better than universally applicable. Every time.
Both TPU 8t and TPU 8i arrive on Google Cloud later in 2026.
The kitchen was shared. The restaurant is true to scale.
Sources:
- TPU 8t and TPU 8i technical details – Google Cloud blog
- Sundar Pichai’s keynote at Google I/O 2026
- Google Cloud Next 2026 – Sundar Pichai
![]()
TPU Just Got Split in Two — and It’s Changing Everything About AI Infrastructure was originally published in Google Developer Experts on Medium, donde la gente continúa la discusión resaltando y respondiendo a esta historia.