大規模な言語モデルの実行 (LLM) モバイルデバイスでの利用はかつては未来の夢でした. 今日, Googleのリリースに伴い ジェマ 4 家族と権力者 LiteRT-LM フレームワーク, 高性能を実現, マルチモーダル モデルをスマートフォンに直接接続できるだけでなく、, しかし、非常に効率的でもあります.
この投稿では, Gemma の建築上の飛躍を探ります 4, LiteRT-LM がオンデバイス推論を調整する方法, NPU アクセラレーションにおけるクアルコムの QNN の役割, 2.58GB AI モデル向けの実稼働対応 Android アプリケーションを構築するために必要な実際的な技術的変更.
ジェマ 4 建築
Googleのジェマ 4 オープンウェイトエッジモデルの大きな飛躍を意味する ジェマ 4 E2B (有効な最大 20 億パラメータ) このモデルはモバイルおよびエッジ環境向けに特別に調整されており、いくつかの重要な革新をもたらします。:
- ネイティブのマルチモダリティ: テキストのみが含まれていた以前のイテレーションとは異なります, ジェマ 4 テキストをネイティブに理解する, 画像と音声. 可変アスペクト比ビジョンエンコーダを使用しており、コンテキストを損なうことなくさまざまな解像度で画像を処理できます。.
- レイヤーごとの埋め込み数 (プル): この手法により、埋め込みのメモリ フットプリントが削減されます。, これは、Android スマートフォンなどの共有 RAM アーキテクチャを備えたデバイスにとって重要です。.
- 共有KVキャッシュ: コンテキスト管理の効率を向上させます, モデルが最大で簡単に扱えるようになります。 32Kトークンコンテキストウィンドウ ストレージのピークを最小限に抑えながら.
エンジンのアーキテクチャ: LiteRT および LiteRT-LM
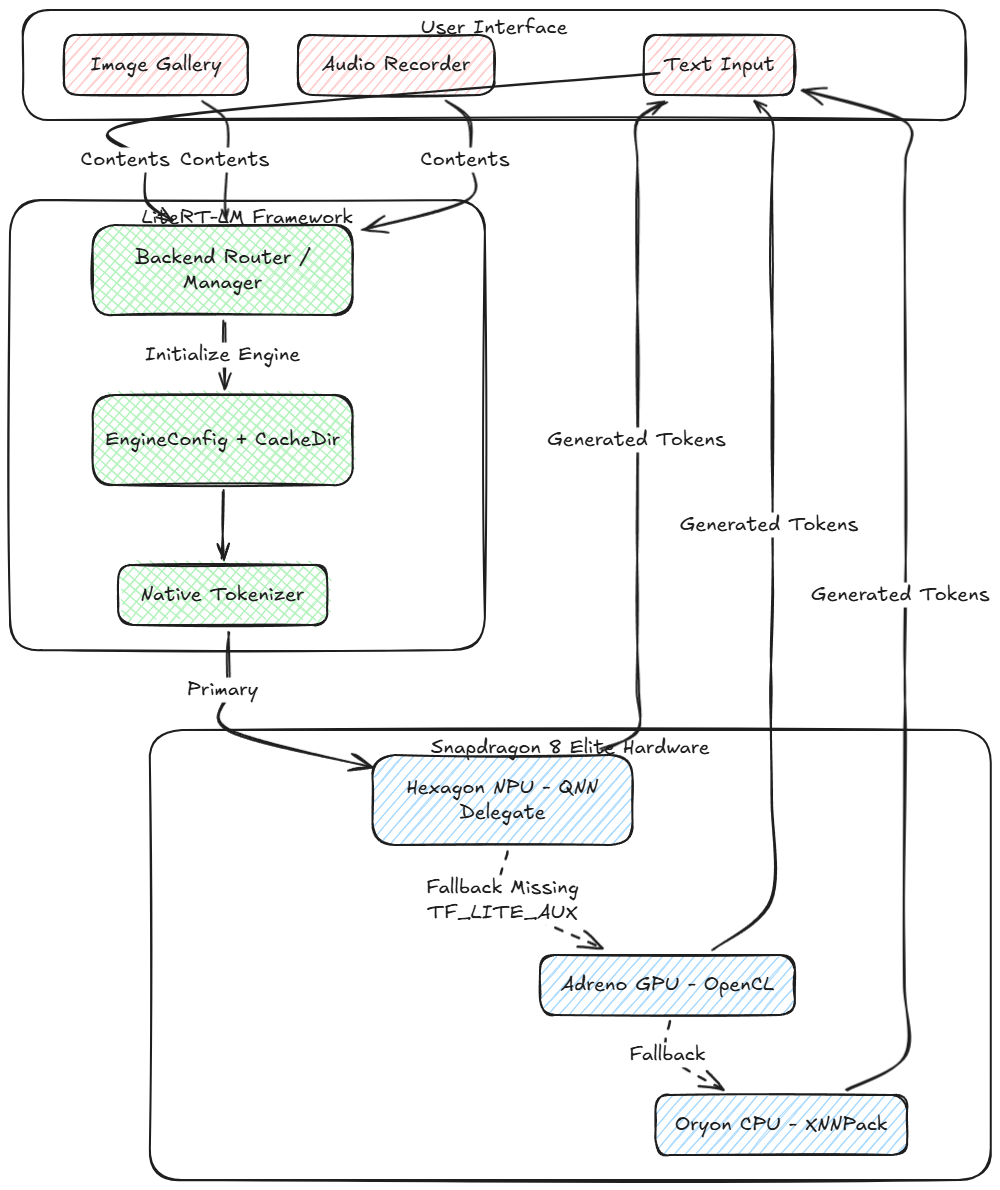
Android でこの複雑なモデルを実行するために使用するのは リットルRT (以前の TensorFlow Lite) その隣に LiteRT-LM (大規模モデル向け LiteRT). 2 つの違いを理解することが、デバイス上で AI を使いこなす鍵となります.
LiteRT: 実行層
最低レベルで, リットルRT ニューラル ネットワークの静的計算グラフの実行を担当するランタイム エンジンです。. 数学的な操作が必要です (ママル, 追加, ソフトマックス) .litertlm で定義されている (または .tflite) ファイルを作成し、物理ハードウェア全体にマップします。 代表者.
- XNNPack デリゲート (CPU): ARM コア向けに高度に最適化されたベクトル演算.
- OpenCL/ML ドリフト (GPU): Adreno GPUの並列計算機能を利用.
- QNN 代表者 (NPU): 量子化された整数演算を Hexagon NPU に移行して効率を最大化します.
LiteRT-LM: オーケストレーション層
大規模な言語モデルでは、グラフを実行するだけでは十分ではありません。. アクティブな, ステートフルループ. LiteRT-LM C++ オーケストレーション層として機能します (Kotlin/JNI API にエレガントにパッケージ化) それは座っています その上 リットルRT. LLM 推論の膨大な複雑さを抽象化します。:
- ネイティブのトークン化と非トークン化: Python や遅い Java 実装に依存するのではなく, LiteRT-LM は高度に最適化された C++ トークナイザーに直接バインドします (通常は SentencePie または BPE) テキストをエンコードする, オーディオ, Gemma が期待する整数配列へのビジョン トークン.
- KVキャッシュ管理: LLM 内, 次の単語を予測するには、前のコンテキストを記憶する必要があります. LiteRT-LM が自動的に割り当てます, 管理する, Key-Value を更新します (KV) 生成された各トークンのキャッシュ テンソル. ジェマ 4 新しいものに上手に対処する 共有KVキャッシュ メモリ要件を最小限に抑えるアーキテクチャ.
- サンプラーの構成: 自己回帰生成ループを管理し、選択されたトークンを LiteRT グラフにフィードバックする前に、C++ でネイティブに Top-K や Top-P サンプリングなどのアルゴリズムを適用します。.
- マルチモーダルコンテンツルーティング: Content.ImageFile と Content.AudioBytes の配列を取得します。, それらを特定のビジョン/オーディオ エンコーダのサブグラフに渡します, そしてそれらをテキストトークンとともに統合された埋め込み空間に投影します.
クアルコム QNN に参入
サムスン S25 ウルトラ (スナップドラゴンを搭載 8 エリート) 強力な Hexagon NPU を搭載. を使用することで、 クアルコム ニューラル ネットワークの代表者 (QNN).LiteRT は、トランスフォーマー ブロックの大規模な行列乗算を CPU/GPU から NPU に直接オフロードできます。. これにより、電力消費とサーマル スロットリングが大幅に削減され、1 秒あたりのトークン数が最大化されます。 (TPS).
しかし, NPUを使用するには, モデルには特定のプリコンパイルされた QNN ペイロード バイナリが含まれている必要があります (TF_LITE_AUX). これらがない場合, 堅牢なアプリは GPU に適切に依存する必要があります (OpenCL/MLドリフトを使用) またはCPU (XNNPackを使用した場合).
システムアーキテクチャと技術的な変更
Android アプリケーションを Gemma からアップグレードするとき 3 ジェマへ 4, いくつかの技術的なハードルに遭遇しました – API から、最新の Android ストレージ ルールに基づいて巨大な 2.58GB ペイロードを処理するように移行.
これは、新しい推論パイプラインがデバイス上でどのように動作するかを視覚的に表現したものです。:
![写真[1]-マルチモーダルジェマの実現 4 E2B からエッジまで: Windows 7、8、10、11 向けの LiteRT-LM と Qualcomm QNN の詳細 - Winpcsoft.com](https://winpcsoft.com/wp-content/plugins/wp-fastest-cache-premium/pro/images/blank.gif)
重要な実装のアップグレード
1. LiteRT-LM コアのアップグレード
Gemma 4 のアーキテクチャ (特に PLE と新しい共有 KV キャッシュ) 最新のランタイムが必要です. 新しいモデル構造との互換性を確保するために、LiteRT-LM Android ライブラリの最新バージョンをプルするようにビルド構成を更新しました。.
2. マルチモーダル API 統合
Gemma 4 の画像および音声機能のロックを解除するには, LiteRTLManager を再設計しました. プレーンテキストの sendMessage から移行しました() 新しいマルチモーダル コンテンツ ビルダーの呼び出し:
val contentParts = mutableListOf<コンテンツ>()
contentParts.add(Content.ImageFile(画像パス))
contentParts.add(Content.AudioBytes(オーディオバイト))
contentParts.add(コンテンツ.テキスト(テキストプロンプト))
val 内容 = 内容.of(*contentParts.toTypedArray())
さらに, EngineConfig が更新され、特にビジョンとオーディオのサブモデルにバックエンド デリゲートを割り当てるようになりました。 (例えば. 音声は CPU に残ったまま、前方視界を GPU に転送).
3. 2.58GB ペイロードの壁を克服 (ADB プッシュ ワークフロー)
Android アプリで標準 HTTP 接続経由で 2.58GB モデルを直接ダウンロードすると、本質的に不安定になります. モバイルネットワークがダウンしています, HttpURLConnection にはリダイレクトと Android に関する問題があります 15 エリア限定ストレージ /sdcard/Download/ などのパブリック フォルダーへのアプリのアクセスを厳しく制限します。.
解決策: ダイレクトADBプッシュ検出システムを実装しました. アプリ内ダウンロードに依存するのではなく, 開発者とユーザーはモデルを自分の PC に安全にダウンロードし、アプリの無制限の外部データ ディレクトリに直接転送できます。:
adb Push gemma-4-E2B-it.litertlm /sdcard/Android/data/com.example.qnn_litertlm_gemma/files/
アプリの ModelDownloader クラスが起動時にこれをキャッチします, ペイロードサイズを検証します, コピーやダウンロードを行わずにすぐにエンジンを初期化します。, ロード時間を大幅に短縮し、SocketException を排除します。.
4. NPU → GPU → CPU フォールバック チェーン
オープンソースモデルの重み付けのため (ハグフェイスのもののように) 多くの場合、デバイス固有のプリコンパイル済み QNN バイナリが欠落しています, NPU 接続を強制するとアプリがクラッシュする可能性があります.
NPU をスピンアップしようとする遅延読み込み BackendFactory を実装しました。. LiteRtLmJniException がスローされた場合 (TF_LITE_AUX が見つからなかったことを具体的に報告), アプリはすぐに例外をキャッチします, NPUを終了します, 代わりに OpenCL GPU バックエンドをシームレスに初期化します.
ディプロマ
Gemma のデプロイ 4 Android デバイス上の E2B は、Edge AI がいかに急速に進化しているかを証明しています。. Google の高度に最適化されたモデルを組み合わせることで, LiteRT-LM の抽象化, そしてクアルコムのハードウェアアクセラレーション, 私たちは真実を達成することができます, プライベート, マルチモーダルインテリジェンスをポケットに.
ストレージ権限に技術的なボトルネックがある, フォールバックルーティング, 依存関係管理が解決されました, プライバシーを重視した次世代の技術を開発するための基礎が築かれました, コンテキスト認識型モバイル アプリケーション.
![]()
マルチモーダルジェマの実現 4 E2B からエッジまで: LiteRT-LM と Qualcomm QNN の詳細は、当初 Google Developer Experts on Medium で公開されました。, 人々がこのストーリーをハイライトして応答することで会話を続けている場所.