Exécution de grands modèles de langage (LLM) sur les appareils mobiles était un rêve d'avenir. Aujourd'hui, avec la sortie de Google Gemme 4 La famille et les puissants LiteRT-LM Cadre, offrant des performances élevées, les modèles multimodaux directement sur un smartphone sont non seulement possibles, mais aussi extrêmement efficace.
Dans cet article, nous explorons les sauts architecturaux de Gemma 4, comment LiteRT-LM orchestre l'inférence sur l'appareil, le rôle de Qualcomm’s QNN pour l'accélération NPU, et les modifications techniques pratiques nécessaires pour créer une application Android prête pour la production pour un modèle AI de 2,58 Go.
La Gemme 4 architecture
Google’Gemma 4 représente un progrès significatif pour les modèles de bord à poids ouvert Gemme 4 E2B (Efficace ~ 2 milliards de paramètres) Le modèle est spécifiquement adapté aux environnements mobiles et de périphérie et apporte plusieurs innovations clés:
- Multimodalité native: Contrairement aux itérations précédentes qui ne contenaient que du texte, Gemme 4 comprend nativement le texte, images et sons. Il utilise un encodeur de vision à rapport d'aspect variable qui lui permet de traiter des images à différentes résolutions sans compromettre le contexte..
- Incorporations par couche (PLÉ): Cette technique réduit l'empreinte mémoire des intégrations, ce qui est crucial pour les appareils dotés d'une architecture RAM partagée comme les téléphones Android.
- Cache KV partagé: Améliore l’efficacité de la gestion du contexte, permettant au modèle de gérer facilement jusqu'à un 32Fenêtre contextuelle du jeton K tout en minimisant les pics de stockage.
L'architecture du moteur: LiteRT et LiteRT-LM
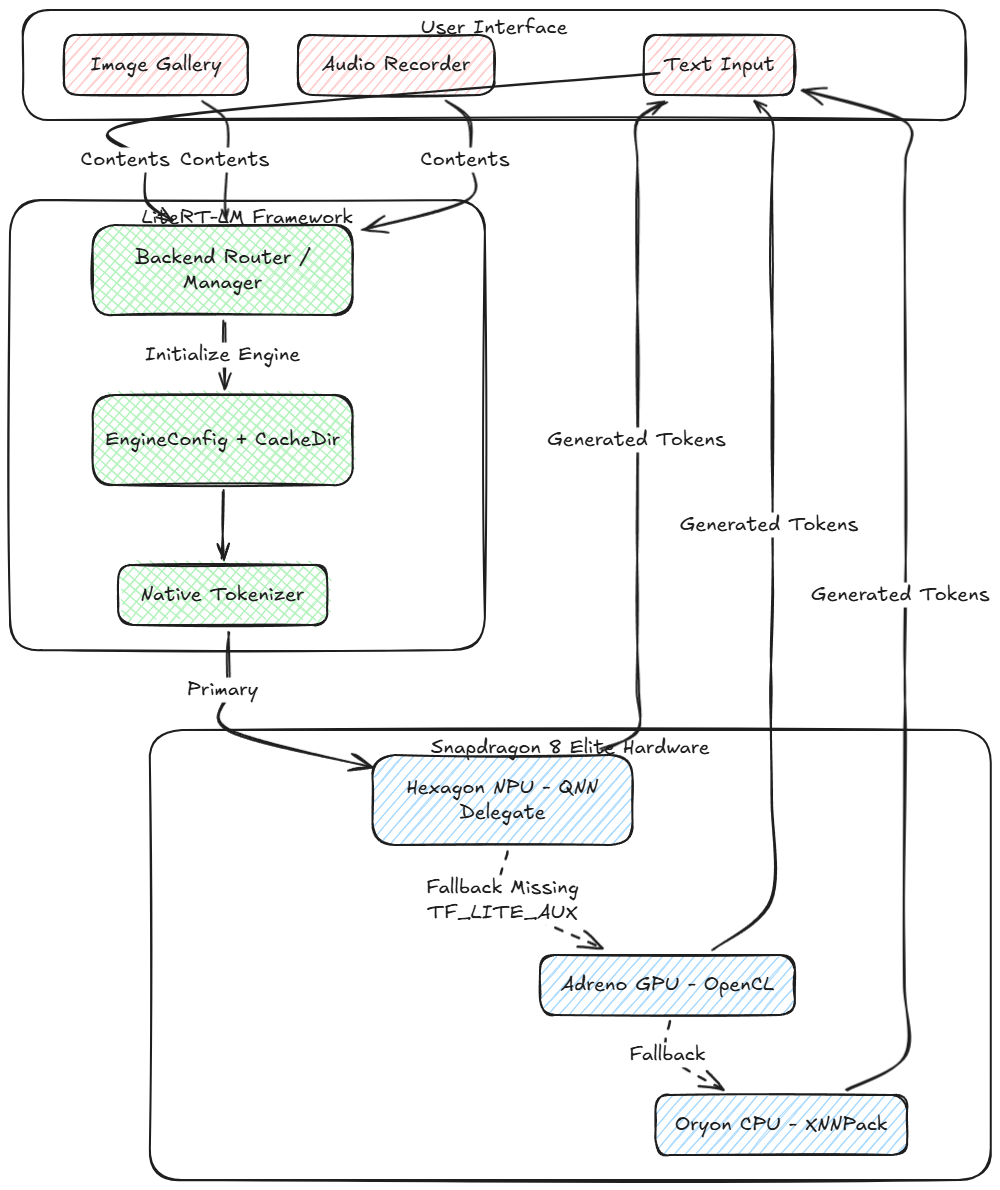
Pour exécuter un modèle de cette complexité sur Android, nous utilisons LitreRT (anciennement TensorFlow Lite) à côté LiteRT-LM (LiteRT pour les grands modèles). Comprendre la différence entre les deux est essentiel pour maîtriser l’IA sur appareil.
LiteRT: La couche d'exécution
Au niveau le plus bas, LitreRT est le moteur d'exécution responsable de l'exécution du graphique de calcul statique du réseau neuronal. Il faut les opérations mathématiques (MatMul, Ajouter, Softmax) défini dans le .litertlm (ou .tflite) fichier et les mappe sur le matériel physique délégués.
- Délégué XNNPack (Processeur): Mathématiques vectorielles hautement optimisées pour les cœurs ARM.
- Dérive OpenCL/ML (GPU): Utilise des fonctions de calcul parallèle sur le GPU Adreno.
- Délégué QNN (NPU): Déplace les opérations entières quantifiées vers le NPU Hexagon pour une efficacité maximale.
LiteRT-LM: La couche d'orchestration
Les grands modèles de langage nécessitent bien plus que la simple exécution de graphiques. Ils nécessitent un actif, boucle avec état. LiteRT-LM agit comme une couche d'orchestration C++ (élégamment emballé dans une API Kotlin/JNI) qui est assis au-dessus de LitreRT. Il résume l'énorme complexité de l'inférence LLM:
- Tokenisation et détokenisation natives: Au lieu de s'appuyer sur Python ou sur des implémentations Java lentes, LiteRT-LM se lie directement à un tokenizer C++ hautement optimisé (généralement SentencePièce ou BPE) encoder du texte, audio, et des jetons de vision dans les tableaux d'entiers attendus par Gemma.
- Gestion du cache KV: En LLM, prédire le mot suivant nécessite de se souvenir du contexte précédent. LiteRT-LM attribue automatiquement, gère, et met à jour la clé-valeur (KV) tenseurs de cache pour chaque jeton généré. Gemme 4 gère le nouveau avec habileté Cache KV partagé Architecture pour minimiser les besoins en mémoire.
- Configuration de l'échantillonneur: Il gère la boucle de génération autorégressive et applique des algorithmes tels que l'échantillonnage top-K et top-P de manière native en C++ avant de réinjecter le jeton sélectionné dans le graphe LiteRT..
- Routage de contenu multimodal: Il récupère des tableaux de Content.ImageFile et Content.AudioBytes, les fait passer par les sous-graphiques spécifiques de l'encodeur vision/audio, et les projette dans l'espace d'intégration unifié avec des jetons de texte.
Entrez Qualcomm QNN
Le Samsung S25 Ultra (propulsé par le Snapdragon 8 Élite) dispose d'un puissant NPU Hexagon. En utilisant le Délégué du réseau de neurones Qualcomm (QNN).LiteRT peut décharger les multiplications matricielles massives des blocs de transformateur du CPU/GPU directement vers le NPU. Cela réduit considérablement la consommation d'énergie et la limitation thermique et maximise le nombre de jetons par seconde. (TPS).
Cependant, utiliser le NPU, le modèle doit contenir des binaires de charge utile QNN précompilés spécifiques (TF_LITE_AUX). En l'absence de ceux-ci, une application robuste doit correctement s'appuyer sur le GPU (avec dérive OpenCL/ML) ou le processeur (avec XNNPack).
Architecture du système et modifications techniques
Lors de la mise à niveau de notre application Android depuis Gemma 3 à Gemma 4, nous avons rencontré plusieurs obstacles techniques – de l'API passe à la gestion d'une énorme charge utile de 2,58 Go selon les règles de stockage Android modernes.
Voici une représentation visuelle du fonctionnement du nouveau pipeline d'inférence sur l'appareil:
![image[1]-Apporter Gemma multimodal 4 E2B jusqu'au bord: Une plongée approfondie dans LiteRT-LM et Qualcomm QNN pour Windows 7,8,10,11-Winpcsoft.com](https://winpcsoft.com/wp-content/plugins/wp-fastest-cache-premium/pro/images/blank.gif)
Mises à niveau importantes de la mise en œuvre
1. Mise à niveau du noyau LiteRT-LM
Gemme 4’l'architecture (en particulier PLE et le nouveau cache KV partagé) nécessite le dernier runtime. Nous avons mis à jour notre configuration de build pour extraire la dernière version des bibliothèques Android LiteRT-LM afin de garantir la compatibilité avec la nouvelle structure de modèle..
2. Intégration d'API multimodale
Pour débloquer Gemma 4’Fonctionnalités image et audio, nous avons repensé notre LiteRTLMManager. Nous’Je suis passé du texte brut sendMessage() appels au nouveau générateur de contenu multimodal:
val contentParts = mutableListOf<Contenu>()
contentParts.ajouter(Contenu.ImageFile(cheminimage))
contentParts.ajouter(Contenu.AudioBytes(octets audio))
contentParts.ajouter(Contenu.Texte(invite de texte))
contenu val = Contenu.de(*contentParts.toTypedArray())
En plus, EngineConfig a été mis à jour pour allouer des délégués backend spécifiquement pour les sous-modèles de vision et audio (par exemple. vision directe vers le GPU tandis que l'audio reste sur le CPU).
3. Surmonter la barrière de charge utile de 2,58 Go (Flux de travail push ADB)
Le téléchargement d'un modèle de 2,58 Go via une connexion HTTP standard directement dans une application Android est intrinsèquement instable. Les réseaux mobiles sont en panne, HttpURLConnection a des problèmes avec les redirections et Android 15 Stockage limité à une zone restreint considérablement l'accès des applications aux dossiers publics tels que /sdcard/Download/.
La solution: Nous avons mis en place un système de détection push ADB direct. Au lieu de compter sur les téléchargements intégrés à l'application, les développeurs et les utilisateurs peuvent télécharger le modèle en toute sécurité sur leur PC et le transférer directement vers l'application’s répertoire de données externes sans restriction:
adb push gemma-4-E2B-it.litertlm /sdcard/Android/data/com.example.qnn_litertlm_gemma/files/
L'application’La classe ModelDownloader détecte cela au démarrage, valide la taille de la charge utile, et initialise le moteur immédiatement sans copier ni télécharger, réduisant considérablement les temps de chargement et éliminant les SocketExceptions.
4. La chaîne de secours NPU → GPU → CPU
Depuis que les pondérations des modèles open source (comme ceux de Hugging Face) il manque souvent les binaires QNN précompilés spécifiques à l'appareil, forcer une connexion NPU peut provoquer le crash de l'application.
Nous avons implémenté un BackendFactory à chargement paresseux qui tente de faire tourner le NPU. Lorsqu'une LiteRtLmJniException est levée (signalant spécifiquement que TF_LITE_AUX n'a pas été trouvé), l'application détecte immédiatement l'exception, quitte le NPU, et initialise de manière transparente le backend GPU OpenCL à la place.
Diplôme
Déploiement de Gemma 4 E2B sur un appareil Android témoigne de la rapidité avec laquelle Edge AI évolue. En combinant Google’s modèles hautement optimisés, LiteRT-LM’l'abstraction, et Qualcomm’s accélération matérielle, nous pouvons réaliser vrai, privé, l'intelligence multimodale directement dans nos poches.
Avec les goulots d'étranglement techniques dans les autorisations de stockage, routage de secours, et gestion des dépendances résolue, les bases sont posées pour développer la prochaine génération de solutions axées sur la confidentialité, applications mobiles contextuelles.
![]()
Apporter Gemma multimodal 4 E2B jusqu'au bord: Une plongée approfondie dans LiteRT-LM et Qualcomm QNN a été initialement publiée dans Google Developer Experts sur Medium, où les gens poursuivent la conversation en soulignant et en répondant à cette histoire.