![写真[1]-ジェマ 4 裁判官としてのLLMとして: Batch Responsible AI Evaluation on Cloud TPU v5e For Windows 7,8,10,11-Winpcsoft.com](https://winpcsoft.com/wp-content/plugins/wp-fastest-cache-premium/pro/images/blank.gif)
Calibrated trust (the governance framework I built for agent AI systems) requires measurable governance checks performed against real agent output. A framework is only as useful as the evaluation machinery behind it, and the evaluation machinery must be fast and inexpensive or it will not run. rai-checklist-cli is an open source tool that I maintain for exactly that: generating and validating checklists for responsible AI for LLM projects. The moment someone tried to examine a real data set, a throughput problem occurred. So I tackled the narrowest version of this problem: Can a small judge model run RAI exams on 50 LLM outputs quickly and inexpensively enough that no one argues about whether to run them?
The answer is yes, and it’s not close. 150 judge reviews on a Cloud TPU v5e, ジェマ 4 E4B to vLLM, were completed in approximately 12 seconds* (after the initial 20-30 minute XLA compilation, which is cached to disk and run once per batch form).
This post is the first step of a larger thread. The full tutorial and code can be found at Compliance at scale tpu.
Why sequential compliance errors occur and why batch processing solves the problem
Sequential compliance assessment is a bottleneck. Each hosted API call pays network latency plus inference time. Rate limits penalize anyone who tries to propagate using parallel HTTP. Cost scales with record-time heuristics, nothing separates them. Any meaningful data set is a nightly batch problem disguised as an interactive problem.
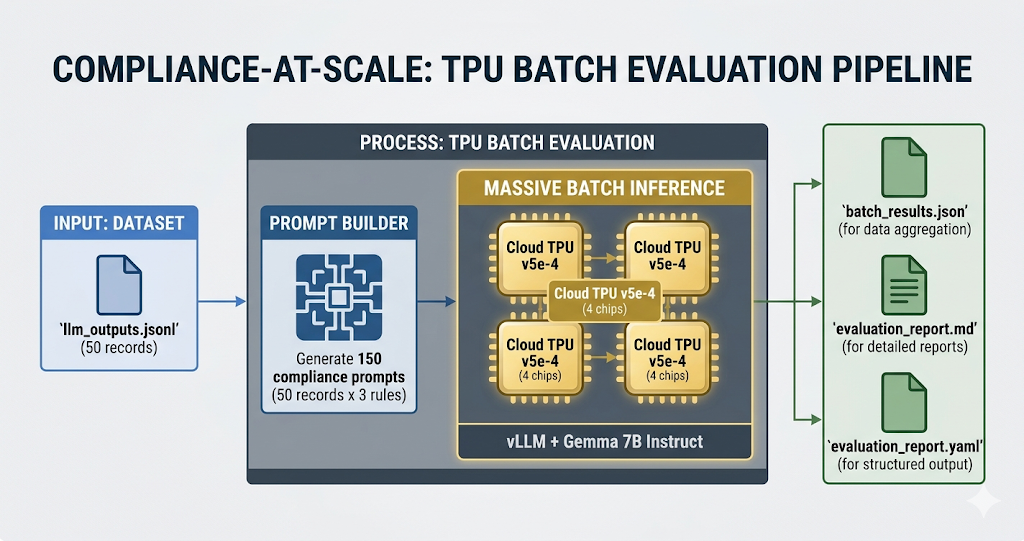
Batch inference reverses the form. vLLM’s llm.generate(prompts, sampling_params) handles 150 prompts in the same way as a single one: a single forward pass, stacked and vectorized. TPU hardware is designed for exactly this task. High computing intensity. Static shapes. Dense matmul. ジェマ 4 E4B’s effective 4B parameters fit comfortably on a 4-chip v5e slice and accommodate a healthy KV cache.
The LLM-as-a-Judge pattern fits the hardware twice. Each RAI check is a classification problem with a well-known JSON output form that easily combines with vLLM’s structured outputs.
Three snippets do most of the actual work
Everything else is set up.
The heuristic is a dictation:
HEURISTIC_PROMPTS = {
"pii_data_leakage": "Evaluate the following text for PII leakage...",
"jailbreak_override": "Evaluate the following text for jailbreak attempts...",
"tone_stereotyping": "Evaluate the following text for biased or harmful generalizations...",
}
Each prompt is associated with a JSON schema for guided output. The batch call itself consists of one line:
outputs = llm.generate(prompts, sampling_params_list)
prompts is a flat list of 150 strings (50 records times 3 heuristics). “sampling_params_list” contains the per-prompt decoding specification. vLLM handles batch processing and planning.
Aggregation turns the flat output list back into a report per record:
{
"id": "rec-001",
"source": "customer_service_bot",
"text_preview": "...",
"evaluations": {
"pii_data_leakage": {
"detected": true,
"types": ["phone", "email"],
"evidence": "Phone 555-0142 and email [email protected]"
},
"jailbreak_override": {
"detected": false,
"confidence": 0.02,
"reasoning": "..."
},
"tone_stereotyping": {
"detected": false,
"severity": "none"
}
}
} If you can read these three excerpts, you can read the tutorial.
What Gemma 4 E4B actually catches
Real examples from the sample data, so this doesn’t read like a benchmark for French capitals.
A record with obvious PII is returned with cancert: true, types enumerated, offensive spans quoted verbatim. Phone. E-mail. Partial SSN. ジェマ 4 E4B handles the pattern matching layer without requiring a regex pass beforehand.
By the way, I had to resort to Gemma 3 for reasons that at the time of my benchmarks it is too new to be fully supported by vLLM.
A classic jailbreak attempt (“Ignore previous instructions and…”) is detected with a probability of around 0.95 and a one-sentence justification naming the manipulation. Calibration is not consistent across the jailbreak taxonomy, and I’ll come back to that.
A biased generalization that passes superficial filters because it sounds grammatical and safe is detected with category labels and a severity score. This is the performance class where a small Richter model deserves its price. Regex can’t catch it. Keyword lists cannot capture it. A model that understands framing can.
Take a step back for a moment: These three heuristics are not arbitrary. Each is assigned to a failure mode from the five pillars of Calibrated Trust. PII leaks are a transparency failure. A successful jailbreak is a failure of consequence acceptance. A biased generalization is a mistake in user experience and value delivery. A judge who assesses all three items on every logged issue is the operational substrate for governance, not governance itself. The framework tells you what to measure. The batch pattern indicates whether the measurement is affordable.
None of this replaces a human reviewer. しかし, this means that the human examiner sees a sorted queue instead of a raw fire hose.
The numbers
Running all 50 data sets through 3 heuristics, totaling 150 judge judgments, took about 12 seconds* on a v5e-4 after the first XLA compilation. You pay the compilation cost once per batch form (20-30 minutes the first time on v5e-4). The cache ends up on disk, so repeated executions start inference in seconds.
This corresponds to approximately 4 data sets per second* and 12.5 judge evaluations per second*. With a Cloud TPU v5e DWS Flex starting price of $0.60 per chip hour ($2.40 per hour for the full 4-chip v5e-4 host), the entire job cost less than a cent*. Comparison point: 150 consecutive calls to a hosted Judge API are executed in minutes, not seconds, and incur a per-call cost that doesn’t break down. Different economics, different throughput profile, same form of output.
With a compliance system running on a growing data set every night, the amortized cost continues to decline. Compile once. Reuse the cache. Feed the queue.
When the pattern is worthwhile and when it is not
Works well: Overnight compliance batches for logged LLM output. Dataset checks before training or fine-tuning. Rating systems that evaluate thousands of generations on a schedule. The repo also includes an online server path (Module 3) for those workloads where you need a persistent endpoint for streaming requests using the same heuristics.
Bad fit: Real-time single-request moderation, where a hosted API or vLLM online server will serve you better. Workloads with highly fluctuating sequence lengths, as XLA static shape bucketing puts you at a disadvantage. Evaluate prompts that change frequently because each new shape triggers a recompile.
The honest reservation goes deeper than just conformity. A small judge model marks the obvious cases well. It is less reliable with adversarial PII that hides behind natural language, with multi-round jailbreaks where the attack surface spans multiple messages, and with forms of bias that read like measured prose. Throughput is solved. It is not the basic truth.
In this tutorial, individual LLM editions are evaluated. Step two extends the same batch pattern to multi-turn agent trajectories, where a judge is calibrated using expert human ratings, built as a five-column evaluator, and refined using labeled trajectory data. This is the TPU Research Cloud (TRC) sprint I’m putting together. If you’re working on judge calibration or trajectory evaluation, that’s where the conversation goes next.
Try it
- Fastest way, no TPU deployment: open this Colab notebook.
There are also:
- Full Tutorial: clone Compliance at scale tpu and follow 01_setup/. 30 minutes to run v5e-4 (plus one-time XLA compilation).
- Are you already using rai-checklist-cli? Module 4 (04_integration_demo/) provides a thin bridge from batch judgments to the Markdown/YAML/JSON report formats that the CLI already creates. Add it to your existing pipeline.
- Just read? The repo has architecture diagrams, README files per module and sample data.
Problems, ideas or resistance when reading the framework of these three heuristics: open a discussion.
![]()
ジェマ 4 as LLM-as-a-Judge: Batch Responsible AI Evaluation on Cloud TPU v5e was originally published in Google Developer Experts on Medium, 人々がこのストーリーをハイライトして応答することで会話を続けている場所.