introduction
In early April 2026, Google released Gemma 4, the latest family of open multimodal models, and momentum has been building ever since. Gema 4 is available in four sizes: Effective 2B (E2B), Effective 4B (E4B), 26B Mixture of Experts (Ministério da Educação) and 31B Dense. The Gemma family’s native multimodality debuted last year with Gemma 3.
What’s special about Gemma 4 is that it goes beyond standard text-to-text chat and can handle complex considerations and agent workflows. In practice, the real challenge lies in operating these models efficiently. This leads to a natural question: How do LLMs like Gemini provide answers in a split second? A big part of the answer lies in TPUs.
![foto[1]-Servir e inferir Gemma 4 on TPU For Windows 7,8,10,11-Winpcsoft.com](https://winpcsoft.com/wp-content/plugins/wp-fastest-cache-premium/pro/images/blank.gif)
Tensor Processing Units (TPUs)
Google uses Tensor Processing Units (TPUs) as hardware accelerators for both training and deployment models. What puts Google at the forefront of the AI competition is its early investment in developing custom chips designed specifically for large-scale machine learning tasks.
In practice, these accelerators can deliver significantly higher performance than general-purpose GPUs for certain model architectures and deployment scenarios.
In this blog, I go beyond the usual VLM inference on GPUs and show how to create a TPU instance in Google Cloud to deploy Gemma 4 using vLLM.
What is vLLM?
vLLM is an open source, high-performance inference engine for large language models that maximizes hardware utilization and throughput using techniques such as PagedAttention and continuous batching.
Now that we know what TPUs and vLLM are, let’s get started.
Requirements
- Billing account linked to a GCP project
- Reserved TPU quota
- Access the Gemma family of models on Hugging Face
Because TPUs are expensive and have limited availability, you may need to request a quota in advance or use queued resources.
Step 1: Create a TPU instance
Open Google Cloud Console and enable Cloud Shell. TPUs can either be reserved or allocated using queued resources, meaning they are allocated when capacity becomes available.
In Cloud Shell, run the following commands to set up the required variables:
export PROJECT=YOUR_GCP_PROJECT_NAME
export HF_TOKEN=YOUR_HF_TOKEN
export ZONE=southamerica-east1-c
export TPU_NAME=gemma4-tpu-vllm
Cloud TPUs are available in different versions. You can explore the available generations, including the 8th generation TPUs such as TPU 8t (training) and TPU 8i (inference) announced at Google Cloud Next 2026.
In this tutorial I will deploy Gemma 4 on TPU 6e (Trillium).
gcloud alpha compute tpus queued-resources create gemma4-tpu-vllm \
--zone=southamerica-east1-c \
--accelerator-type=v6e-8 \
--runtime-version=v2-alpha-tpuv6e \
--node-id=gemma4-tpu-vllm \
--provisioning-model=flex-start \
--max-run-duration=4h \
--valid-until-duration=4h \
--labels=purpose=flex-start
The above command creates a queued TPU resource using Flex Start deployment, allowing you to specify the duration for which it remains active.
To check the status of your request, follow the steps below
gcloud alpha compute tpus queued-resources describe \
gemma4-tpu-vllm \
--zone=southamerica-east1-c
Depending on availability, it may take some time to spin up the TPU instance.
After deployment, you can see the status has changed to ACTIVE. Alternatively, you can check it in the Cloud Console.
Step 2: Configure firewall
Run the following command to configure firewall rules to allow the vLLM Docker image to allow incoming traffic.
gcloud compute firewall-rules create allow-vllm-8000 \
--allow tcp:8000 \
--target-tags=vllm
Step 3: Connect to the TPU instance via SSH
In Cloud Shell, run the following command to establish an SSH connection to the TPU instance.
gcloud compute tpus tpu-vm ssh gemma4-tpu-vllm \
--zone=southamerica-east1-c
Step 4: Download the Gemma 4 Docker image
Now after SSH connection to the TPU instance, run the following command to download the Gemma 4 Docker image.
sudo docker run -it --rm --name gemma4-vllm \
--privileged \
--network host \
--shm-size 16g \
-v /dev/shm:/dev/shm \
-e HF_TOKEN=$HF_TOKEN \
vllm/vllm-tpu:gemma4 \
python -m vllm.entrypoints.openai.api_server \
--model google/gemma-4-26B-A4B-it \
--tensor-parallel-size 8 \
--max-model-len 8192 \
--limit-mm-per-prompt '{"image": 1, "audio": 0}' \
--disable_chunked_mm_input \
--enable-auto-tool-choice \
--tool-call-parser gemma4 \
--host 0.0.0.0 \
--porta 8000
--allowed-local-media-path /home/nitin_tiwari
In this example, we will deploy the gemma-4-26B-A4B-it model. It is an instruction-tuned model with 26B parameters and 4B active parameters.
Setting up the Docker image takes a few minutes as it loads the model weights and initializes the vLLM inference engine.
Once finished, you should see the following message in the terminal.
Step 5: Start inference
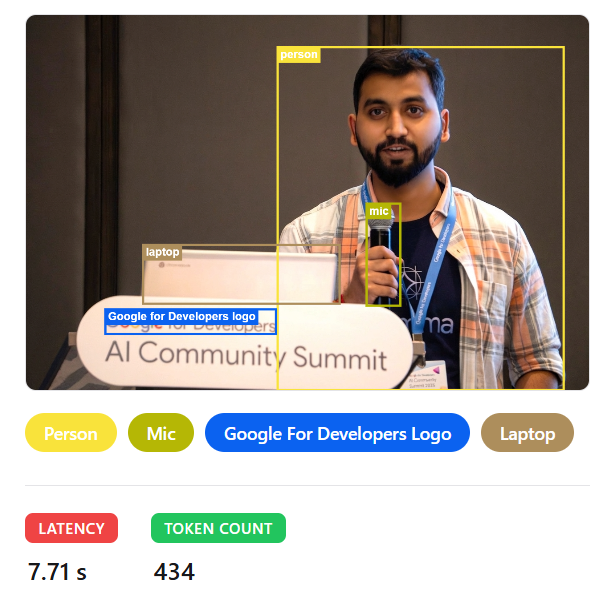
We are now ready to begin inference of the provided model. I created a simple frontend that accepts text and image input, passes it to the TPU instance hosting Gemma 4, and returns the generated response.
Clone the repository to your local computer:
git clone https://github.com/NSTiwari/Gemma-4-on-TPU.git
cd Gemma-4-on-TPU
Once finished, open the index.html file and update line 583 by replacing YOUR_EXTERNAL_IP with the external IP address of your TPU instance:
const res = await fetch("http://YOUR_EXTERNAL_IP:8000/v1/chat/completions"
You can find the external IP address in the list of TPUs in the Google Cloud Console.
Finalmente, start the frontend server with the following command:
# Start frontend server.
py -m http.server
Open your web browser and enter localhost:8000 in the address bar to launch the frontend application.
As you can see, Gema 4 can perform a wide range of tasks with response times of around 2-4 seconds when deployed on TPUs with vLLM.
Observação: The first request may take longer due to the cold start effort.
This concludes this blog. I wanted this blog to cover the end-to-end aspects of how to create a TPU instance in Google Cloud, deploy Gemma 4 using vLLM, create a frontend application and send requests to the TPU instance for inference.
I believe it covers pretty much everything you need to get started and deploy your own custom models on TPUs, where inferences that would otherwise take several seconds to minutes on a typical GPU setup can be significantly faster.
I hope you’ve learned how powerful TPUs can be when combined with vLLM to reduce inference latency. Stay tuned for more such tutorials.
recognition
This project was developed as part of the Google AI Developer Program TPU Sprint. I sincerely thank the Google AIDP team for their generous support in providing GCP credits to support this project.
References and resources
![]()
Servir e inferir Gemma 4 on TPU was originally published in Google Developer Experts on Medium, where people continue the conversation by highlighting and responding to this story.